› Ejercicio detonador
En los siguientes videos encontrará dos entrevistas. La primera a Mario Lavista (1943), compositor mexicano de música de concierto y miembro de El Colegio Nacional, y la segunda a Guillermo Ruíz (2000), joven triatleta mexicano, estudiante de la Facultad de Derecho UNAM.
Entrevista con el compositor Mario Lavista: la música clásica y la música de nuestros días
Video original tomado de aquí
Guillermo Ruíz: “Más allá de las becas hay que crear programas metodológicos para desarrollar atletas”
Video original tomado de aquí
1- Lea primero las siguientes preguntas con atención.
- ¿Cuál de los dos entrevistados imprime más velocidad en su discurso?
- ¿En cuál de las dos entrevistas escucha, en la narración, algunas entonaciones ascedentes, tipo pregunta?
- ¿Podría identificar algún término o frase donde los entrevistados aumentan el volumen de la voz o hacen alguna pausa más larga? En Mario Lavista… en Guillermo Ruíz…
- ¿Qué diferencia de tono (agudo o grave) escucha en estas entrevistas? Tome en cuenta la edad de los entrevistados (76 y 19 años).
- ¿Encuentra alguna diferencia que permita identificar la voz de Lavista y la de Ruíz?
2- Después de haber leído las preguntas escuche las dos grabaciones.
3- Vuelva a leer las preguntas.
4- Escuche dos veces más las grabaciones.
5- Después de haber reflexionado y escuchado estas voces, escriba brevemente la percepción que experimentó sobre estas grabaciones.
¿Qué es la prosodia?
La vía primaria para la trasmisión de un mensaje lingüístico sin lugar a dudas es el habla. El lenguaje tiene un carácter oral esencialmente. La escritura constituye un código subordinado que toma como referente la oralidad.
Antes de explorar la noción que tenemos intuitiva de prosodia, debemos tener presente que en este y otros ámbitos del estudio fónico de las lenguas, la percepción juega un papel fundamental. Así, recordamos que, groso modo la fonética suele clasificarse en tres grandes ámbitos: acústica, articulatoria, y perceptual. El análisis prosódico y estudio del tono se encuentra inscrito en la última. Observa el siguiente esquema que puntualiza el objeto de estudio de cada una de las anteriores clasificaciones:
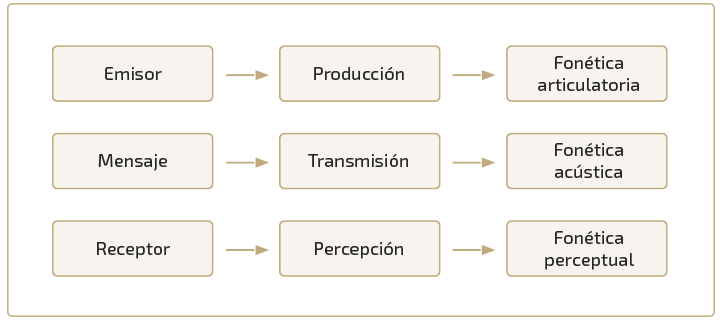
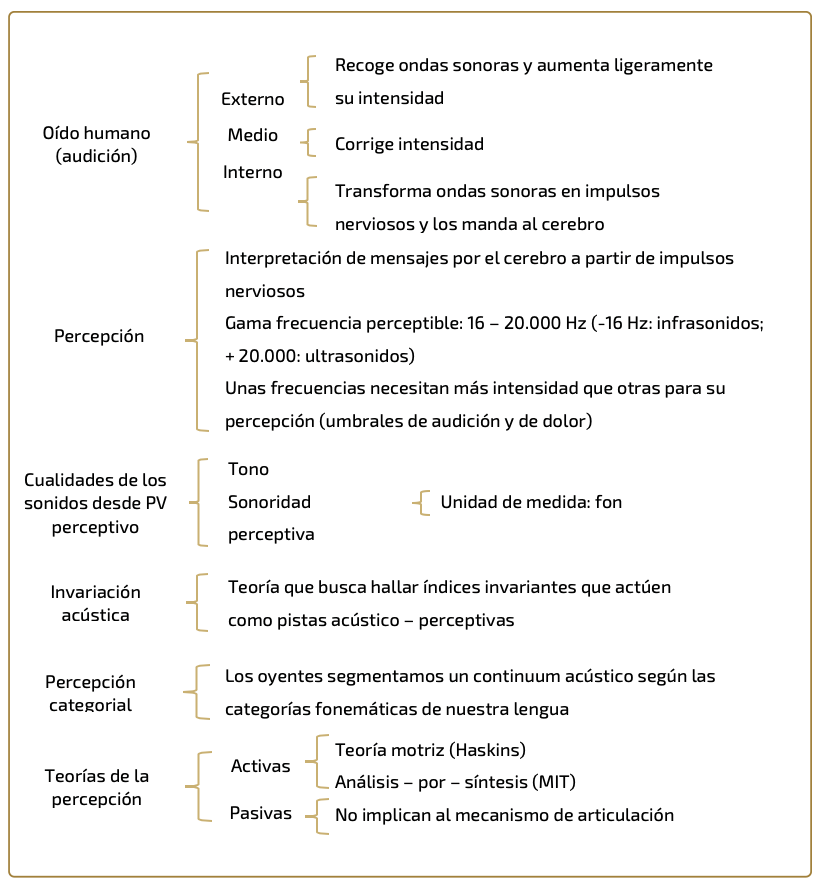
La fonética perceptual o perceptiva precisa el conocimiento y ubicación de los elementos que entran en juego para la descodificación no solo de las frecuencias sonoras sino también de sus rasgos suprasegmentales. En el siguiente esquema tomado de Fernández Planas (2010) se puede apreciar, con bastante claridad, todos y cada uno de los elementos implicados en la percepción fónica.
La entonación
El estudio de la entonación es un tema fundamental, lleno de dificultades y escasamente conocido; de modo que sólo agregaremos que la entonación es un fenómeno que se agrega a la cadena hablada, por ejemplo, “llegó temprano” es una afirmación, “¿llegó temprano?” es una pregunta y “¡llegó temprano!” una exclamación. A cada una de estas oraciones corresponde una intención de parte del emisor y un significado distinto, ambos determinados por la entonación del segmento. A los cuales denominamos aspectos suprasegmentales.
Cuando escuchamos una conversación entre personas que hablan una lengua desconocida por nosotros, ciertamente sólo captamos “porciones” de sonidos correspondientes a ciertas unidades melódicas. En tanto que cuando escuchamos nuestra lengua debido a la familiarización de dichas melodías éstas pasan inadvertidas. Estas porciones melódicas son grupos fónicos.
En un texto escrito los grupos fónicos están, en términos generales, delimitados por los signos de puntuación que específicamente son signos de entonación y de pausa. La pausa es un fenómeno secundario resultante del cambio de entonación. De hecho, en el habla o en la lectura casi siempre se realizan más grupos fónicos de los señalados por las puntuaciones; en este punto podemos señalar la siguiente regla: “a menor velocidad de lectura o enunciación, mayor cantidad de grupos fónicos”.
Todo grupo fónico debe coincidir con una unidad de sentido; así en la oración:
“Mientras ella llegaba cansada, los hijos dormían tranquilamente” podría intentarse esta división en grupos fónicos: “Mientras ella llegaba cansada // los hijos dormían tranquilamente” o esta otra: “Mientras ella llegaba // cansada // los hijos dormían // tranquilamente”; pero nunca: “Mientras ella llegaba cansada los // hijos dormían tranquilamente” pues no se han respetado unidades de sentido.
De lo dicho puede deducirse que: toda lectura de una oración es correcta en tanto se respeten las unidades de sentido.
//: juntura doble barra: representa los finales de grupo fónico menores que la oración; en un texto escrito se encuentran representados por los signos ( ) — , : (paréntesis, guiones, comas, dos puntos, punto y coma);
#: juntura doble cruz: representa el comienzo y el final de una oración;
o: tono medio o llano; 1 tono semiagudo; 2: tono agudo; 3: tono sobreagudo; – 1: tono semigrave; – 2: tono grave; – 3: tono subgrave (el número de tonos y su anotación se apartan del criterio usual entre especialistas; la experiencia docente nos ha inclinado por adoptar este criterio).
En el siguiente texto mostraremos una aplicación: en la línea 1 hacemos coincidir los grupos fónicos con los signos de puntuación; en la 2 separamos como si hiciéramos una lectura más lenta y cuidada:
“Imaginemos un enorme estadio en el que dos importantes equipos
- Imaginemos un enorme estadio en el que dos importantes equipos
- Imaginemos un enorme estadio // en el que dos importantes equipos
rivales disputan un campeonato de fútbol ante una abigarrada
- rivales disputan un campeonato de fútbol ante una abigarrada
- rivales // disputan un campeonato de fútbol // ante una abigarrada
multitud de setenta y cinco mil espectadores que colman las
- multitud de setenta y cinco mil espectadores que colman las
- multitud // de setenta y cinco mil espectadores // que colman las
tribunas. Cualquier movimiento de la pelota en jugada hábil,
- tribunas#Cualquier movimiento de la pelota en jugada hábil//
- tribunas#Cualquier movimiento de la pelota // en jugada hábil//
levanta una ola de excitación que conmueve al público, y casi
- levanta una ola de excitación que conmueve al público // y casi
- levanta una ola de excitación // que conmueve al público // y casi
como una fuerza invisible, arrastra tras de sí a los adeptos
- como una fuerza invisible // arrastra tras de sí a los adeptos
- como una fuerza invisible // arrastra tras de sí // a los adeptos
de uno y otro bando.
- de uno y otro bando#
- de uno y otro bando#
El estudio de los tonos
Pasemos ahora al estudio de los tonos. Para ello nos valdremos de un heptagrama en el que el valor de cada tono se simboliza con los números ya enseñados más arriba:
Or. 1
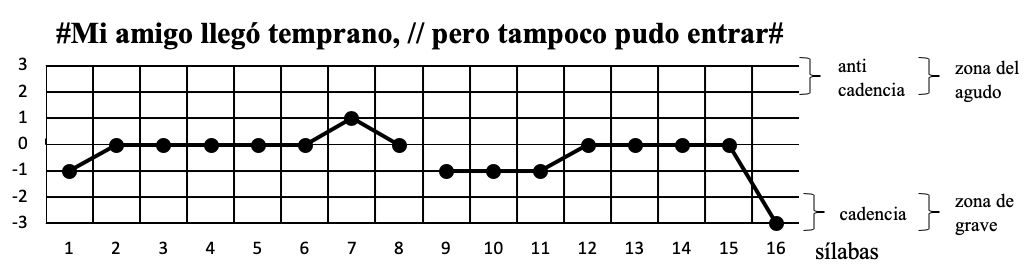
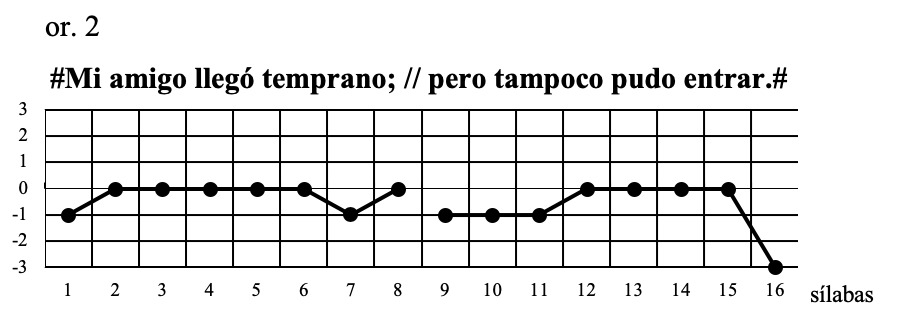
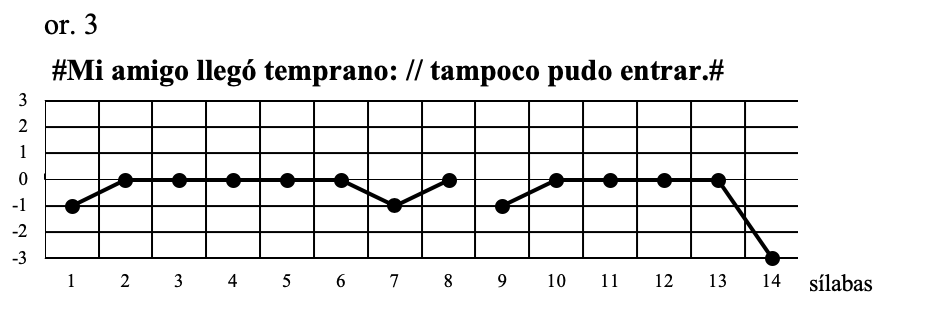
Las tres oraciones precedentes son enunciativas: en ellas se afirma o se niega sin énfasis exclamativo. La diferencia radica en que el primer grupo fónico está limitado por “.” En la or.1, “;” en la 2 y “:” en la 3.
En las tres oraciones el tono arranca por debajo del 0 para alcanzar el 0 en la primera sílaba acentuada (-mi-); desde allí sigue en el mismo tono hasta el último acento del grupo fónico en que: para la oración se eleva al tono 1, y para las 2 y 3 desciende a -1. El segundo grupo fónico comienza como el primero: las sílabas anteriores a la primera acentuada (-po-) se encuentran por debajo del 0, alcanza el tono 0 en la primer sílaba acentuada y siguen en ese tono hasta descender bruscamente al 3, en la última sílaba acentuada (-trar-), en el final de oración.
Por supuesto que estos esquemas corresponden a entonaciones que se toman como estilísticamente neutras, es decir, donde el emisor no tiene ningún interés especial en poner de relieve alguna de sus partes.
De estas observaciones podemos deducir esta regla:
La coma corresponde a un tono semiagudo y el punto y coma y los dos puntos a un tono semigrave;
y esta segunda:
El punto corresponde a un tono grave o subgrave.
¿Va comprendiendo por qué los signos de puntuación son signos de entonación?
Las oraciones interrogativas o exclamativas, a su vez, tienen esquemas de entonación que difieren de las puras enunciativas. Básicamente sería como sigue:


En ambas oraciones se observa cómo el pronombre enfático (interrogativo o exclamativo) alcanza la zona del agudo (para la interrogativa) o sobreagudo (para la exclamativa), lo mismo que la última sílaba acentuada (-pra-). Lo mismo que para las enunciativas, estos esquemas básicos admiten variaciones diversas por factores estilísticos o emotivos.
Merece una explicación la entonación de la coma en las enumeraciones:
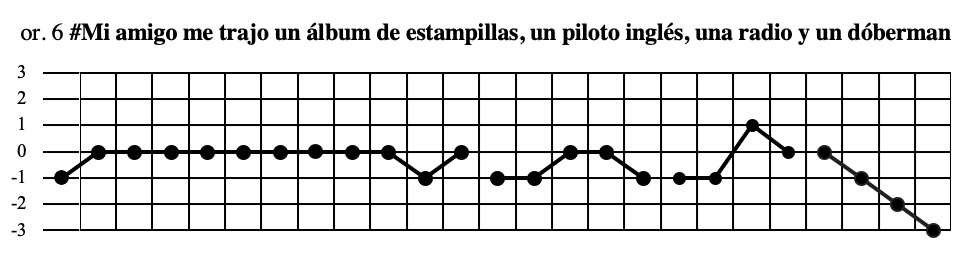
Esta oración enunciativa tiene un objeto directo con una enumeración de cuatro miembros: “un álbum de estampillas”, “un piloto inglés”, “una radio”, “un dóberman”; obsérvese cómo en la última sílaba acentuada de cada miembro enumerativo se desciende hasta el semigrave salvo en el miembro penúltimo, en el que alcanza el semiagudo (típico de la coma).
Con respecto a las incidentales (expresiones aclaratorias que se insertan en la unidad oracional y que van entre comas, guiones o paréntesis) debe señalarse que forman grupo de entonación propio y que siempre se encuentran uno o más tonos por debajo del resto de la oración:

Se observa que cuando un tramo enunciativo llega al 0 en la primera sílaba acentuada, el grupo incidental alcanza el -1; cuando el enunciativo llega al 1 en la coma, el incidental al 0; con esto lo que se quiere poner de relieve es que se entonan por debajo de lo que sería el tramo enunciativo.
Con lo explicado de ninguna manera está agotado el tema de las entonaciones, pero con esto creemos que un maestro cuenta con recursos como para mejorarse y mejorar a sus alumnos auditivamente en la lectura, en la redacción y en la oración oral de todo tipo de textos.
Estos esquemas heptagramados son claros pero un tanto incómodos, por eso puede adoptarse otra notación, como colocar los números correspondientes a los tonos sobre la primera y la última sílaba acentuada de cada grupo fónico o bien señalar el ascenso o descenso de la voz con flechas más o menos largas (con los alumnos de nivel primario, salvo en el último curso, tal vez convenga la notación rigurosa sino que discriminen auditivamente los grupos tonales y los ascensos y descensos de los tonos.
Ejemplos:

La percepción y clasificación general de la entonación
Para el estudio de esta unidad nosotros nos centraremos en los puntos 2 y 3 del esquema anterior. Desde este enfoque perceptual para el estudio del sonido es necesario adentrarnos al estudio de la entonación y su codificación en el proceso auditivo-perceptivo. Para poder constatar lo anterior, es importante considerar que, el primer paso corresponde a la percepción que se tiene al momento de escuchar, tal como lo vimos en los dos apartados anteriores.
Referencias
Botinis, A (2000). Intonation. Analysis, modelling and technology. Dortrecht, Boston, London: Kluwer academiz Publishing.
Cabedo, A. (2007) “Marcas prosódicas del registro coloquial en la conversación”. En Cauce. Revista internacional de Filología y su Didáctica, número 30, pp. 41-56.
Cantero, F (2002). Teoría y análisis de la entonación. Barcelona: Ediciones de la Universidad de Barcelona.
Estebas Vilaplana, E. y Pilar Prieto (coord) (2003): Teorías de la entonación, Barcelona, Ariel.
Fernández Planas, A. Ma. (ed.) (2016). Reflexiones sobre aspectos de la fonética y otros temas de lingüística, pp. 191-199. Barcelona: síntesis.
Fox A. (2000) Prosodic features and prosodic structure. The phonology of suprasegmentals. New York: Oxford University Press.
Iribarren, M (2015). Fonética y Fonología españolas. Cap. 7, pp. 103-124. Madrid: Síntesis.
Local, J; Odgen, R., y Temple, R. (2003). Phonetic interpretation. Papers in laboratoty phonology VI. Cambridgne: Cambridge University Press.
Martín Butragueño, P (2019). Fonología variable del español de México: volumen II: prosodia enunciativa. México: El Colegio de México.
Muñoz A. (2013). “Escudriñando las ondas sonoras del habla”. En A. Pérez, Técnicas para la investigación lingüística y otras disciplinas afines. Cap. I, pp. 15-42. México: Universidad de Colima.
› Siguiente sección – Ejercicio 1
P. Prieto. (2003). Teorías lingüísticas de la entonación. En Estebas Vilaplana, E. y P. Prieto (coords.) Teorías de la entonación. Barcelona: Ariel, pp. 13-34.
CAPÍTULO 1
TEORÍAS LINGÜÍSTICAS DE LA ENTONACIÓN
1.1. Lingüística y entonación
Hablar una lengua no significa simplemente articular una serie de sonidos y palabras una detrás de otra, sino también asignar melodías a los enunciados. Todo hablante de una lengua conoce el sistema particular de contornos melódicos que usa para producir una serie de efectos semánticos compartidos por toda la comunidad lingüística. Como hablantes también somos capaces de identificar los contornos anómalos que no pertenecen al repertorio de nuestra lengua nativa. A lo largo de las últimas décadas se ha hecho cada vez más patente que la entonación es un fenómeno lingüístico que pertenece legítimamente al componente fonológico del lenguaje (véase a tal efecto la argumentación de Ladd, 1996). La existencia de lenguas que utilizan las variaciones tonales para expresar oposiciones de tipo léxico o morfológico (las llamadas lenguas tonales) constituye un argumento a favor del tratamiento fonológico del tono. En lenguas entonativas, como las lenguas románicas, las variaciones melódicas no se usan para distinguir palabras (como hacen las lenguas tonales), sino para manifestar una serie de sentidos pragmáticos que afectan generalmente a todo el enunciado. El carácter lingüístico de la entonación se pone de manifiesto en el hecho de que los patrones melódicos son modelos definidos que se usan para expresar las intenciones comunicativas del hablante. Así, la primera melodía de la figura 1 .1 (gráfico superior izquierda) podría ser una respuesta a una pregunta como ¿Quién viene?; la segunda (gráfico superior derecho) tiene una función apelativa, que utilizamos a menudo cuando llamamos a alguien: la tercera melodía expresa reiteración e intención de comprobar que aquello que se ha oído es cierto ‘¿Acabas de decir que es María?’; y, finalmente, la cuarta tiene una función interpelativa e interrogativa en una frase como ¿Es María?
Además del sentido referencial del mensaje (lo que la gramática tradicional denomina dictum), el hablante, mediante la entonación, manifiesta su actitud subjetiva respecto de ese contenido: el modus. La expresión del modus es esencial en los procesos de interacción comunicativa, puesto que muy a menudo el oyente no está tan interesado en saber qué se ha dicho exactamente (el contenido literal del mensaje), sino en cómo se ha dicho, qué ‘tono’ se ha usado, que es algo que deja entrever la perspectiva del interlocutor. La entonación es un recurso modalizador por excelencia, una característica prosódica que transmite informaciones tan heterogéneas como «estoy dudando, fíjate en esta información, busco confirmación, quiero que hagas esto, aquí termino mi discurso, no te creo, estoy enfadado o quiero enfatizar este hecho». Además de la llamada función expresiva, la entonación también tiene una función focalizadoraen la lengua: el hablante selecciona la información central del mensaje −o la información que desea enfatizar− y le confiere relevancia y prominencia entonativas. Finalmente, la función demarcativa de la entonación es una función indicativa de la partición del discurso y de su organización: el emisor divide el discurso en unidades tonales para que el oyente pueda segmentarlo e interpretarlo con mayor facilidad.
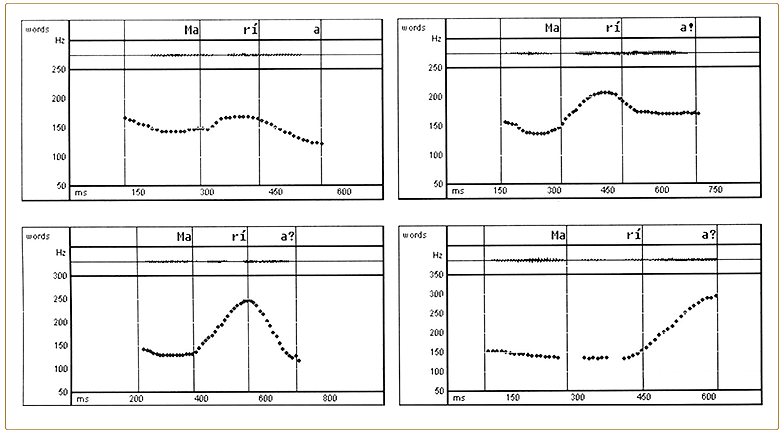
FIG. 1.1. Oscilogramas y contornos de F0 de cuatro patrones entonativos distintos de la secuencia María en español peninsular.
La entonación es un fenómeno lingüístico complejo cuyo tratamiento sistemático precisa de la combinación de tres niveles de análisis complementarios: el eje físico (o la evolución del parámetro físico de frecuencia fundamental a lo largo de la emisión del enunciado), el eje fonológico (las unidades melódicas con importancia significativa en una lengua) y el eje semántico (los efectos significativos que producen esas variaciones melódicas). Tal como ocurre en el plano segmental, presumiblemente los oyentes sólo se percatan de una clase restringida de movimientos tonales que son los que producen contrastes lingüísticos en una lengua determinada, y no de todas las modificaciones fonéticas de la curva melódica. El análisis lingüístico de la entonación pretende poner en relación los ejes físico y funcional de ésta y ‘descubrir’ las unidades tonales capaces de generar oposiciones distintivas o producir diferencias de significado.
Como ya dijo Stockwell (1972), describir la entonación desde el punto de vista lingüístico conlleva dos problemas principales, el de la representación y el del significado. Por un lado, es difícil aplicar a los contornos melódicos los mismos criterios contrastivos que utiliza la fonología segmental, puesto que en lenguas entonativas las variaciones tonales no comportan claras diferencias léxicas (por ejemplo, que moza y moja se diferencian por el punto de articulación de la fricativa), sino matices semánticos que en ocasiones no son fáciles de delimitar. A diferencia de los rasgos segmentales, los suprasegmentales presentan una dificultad adicional de segmentación: en otras palabras, no es tarea fácil decidir cómo se debe segmentar el continuum melódico en una serie de unidades funcionales pertinentes que constituyan la base de la descripción entonativa. La resistencia de la entonación a la sistematización fonológica ha marcado el estudio de este fenómeno, que se ha caracterizado por una relativa marginalidad en el campo de la lingüística y por la coexistencia de enfoques teóricos muy diversos y la falta de un modelo comúnmente aceptado por todos los investigadores. A una situación parecida se refería Navarro Tomás hace ya más de medio siglo.
El mayor obstáculo con que se tropieza en el estudio de esta materia no consiste tanto en la dificultad de medir la altura de los sonidos como en la falta de normas adecuadas y eficaces para interpretar y ordenar de un modo apto para la relación comparativa, histórica y lingüística, el valor de los resultados que con dichas medidas se obtienen. No es la insuficiencia de medios de investigación lo que da lugar a que, no obstante el aumento de publicaciones sobre entonación y el ensayo de algunos trabajos de carácter coordinativo, continúe sin llenar el vacío que hace ya medio siglo señalaba Storm al lamentarse de que aún no se hubiera llegado a determinar en qué consiste concretamente lo peculiar de la entonación de cada lengua (Navarro Tomás, 1944:16).
No obstante, y pese a que históricamente la lingüística ha mantenido una actitud ambigua hacia el estudio de la entonación, las teorías actuales de la entonación, junto con el reciente interés por el componente prosódico del lenguaje han supuesto un gran avance en la comprensión de su funcionamiento. Asimismo, los avances tecnológicos experimentados en los últimos años han sido cruciales en este respecto, ya que hace unos 20 años había pocos laboratorios donde se podía investigar la entonación seriamente.
El objetivo de este capítulo es introducir brevemente los modelos de la entonación que se estudian en este libro y apreciar cómo han ido configurando y aportando un conocimiento más preciso de los ejes fonético, fonológico y semántico de la entonación. Concretamente, se explican algunos elementos diferenciales básicos que facilitarán luego al lector la comparación entre las distintas concepciones de la entonación que plantean las diferentes teorías.
1.2. Modelos lingüísticos de la entonación
Los primeros modelos lingüísticos de la entonación, centrados en la descripción de la prosodia del inglés, surgieron de dos escuelas que iniciaron su actividad hacia principios del siglo xx: la escuela británica (véase García-Lecumberri, cap. 2) y la escuela americana (véase Martínez-Celdrán, cap. 3). Una de las diferencias más notables entre esas dos corrientes radica en el tipo de elementos fonológicos subyacentes que proponen: mientras la escuela británica analiza los contornos melódicos como secuencias de patrones o ‘configuraciones’ expresados mediante movimientos tonales, la escuela americana los analiza mediante una serie de niveles tonales estáticos. De ahí que las propuestas de esas dos corrientes se hayan denominado análisis por configuraciones y análisis por niveles, respectivamente. Asimismo, ambas escuelas se distinguen por el tratamiento que dan a la organización interna de los contornos: la escuela británica separa los contornos en unidades funcionales independientes (cabeza, núcleo y cola), mientras que la escuela americana considera que el contorno central no presenta estructura interna alguna. Otro aspecto que distingue a las dos escuelas es la orientación especialmente fonemicista que caracteriza a la escuela americana. Esta escue la consideró prioritaria la representación formal de los contornos, es decir, la tarea de definir un repertorio de elementos fonemáticos capaces de dar cuenta de los contrastes melódicos en una lengua, y, a diferencia de la aproximación configuracional, dejó de lado la caracterización semántica y fonética de los contornos. Como dice Martínez-Celdrán (cap. 3, §3.5), «la renovación fundamental que necesita la teoría [de la escuela americana] consiste en partir de curvas reales y establecer el nivel fonológico a partir del análisis fonético».
La escuela británica y la americana han marcado profundamente el estudio de la entonación a lo largo del sig lo xx y, como veremos en los capítulos que siguen, los modelos actuales se han ‘inspirado’ claramente en éstas. Por ejemplo, el modelo de la escuela holandesa o modelo IPO (véase Garrido, cap. 5) emplea como unidades mínimas de análisis configuraciones y movimientos tonales (así como una estructura interna de esas unidades en unidades prenucleares y nuclear) parecidos a la propuesta británica y el modelo métrico-autosegmental (véase Hualde, cap. 7) y el de Aixen-Provence (véase Baqué y Estruch, cap. 6) parten de un análisis por niveles similar al de la escuela americana, así como de contornos sin separación interna entre grupo prenuclear y nuclear.
Una de las aportaciones decisivas de los modelos actuales de la entonación, y que los distingue de los modelos tradicionales, es la importancia que se da a la adecuación entre continuum melódico y representación fonológica, que se traduce generalmente en la incorporación de un componente fonético de generación de contornos. Uno de los entonólogos más reconocidos de las últimas décadas, D. Robert Ladd (1996: 12), defiende que tanto el análisis por niveles como el análisis por configuraciones son enfoques ‘protofonológicos’ de la entonación en el sentido que, aunque ambas escuelas tienen como objetivo encontrar las unidades mínimas de análisis entonativo y estudiar los contrastes fonémicos que generan, ninguna de las dos se preocupa de hacer explícita la relación entre la representación fonológica subyacente y la forma melódica final (hecho que, tal como sugiere el mismo autor, quizás responde a la profunda separación entre la fonética y la fonología característica de la época). En la actualidad se considera que todo modelo lingüístico de la entonación debe incluir un componente de implementación fonética que haga explícito cómo se transforma la representación fonológica subyacente en el continuum de variación melódica. Dar cuenta de ese vínculo es el único camino para eliminar la posible ambigüedad a la hora de atribuir las variaciones melódicas bien al componente fonético, bien al fonológico, y obtener un tratamiento lo suficientemente adecuado. En definitiva, los modelos actuales de la entonación contienen como mínimo los dos componentes siguientes:
- un componente fonológico que caracteriza las curvas melódicas mediante una serie (inventario) de unidades contrastivas;
- un componente fonético que describe de forma explícita el vínculo existente entre la forma subyacente de las curvas y el continuum melódico.
La escuela holandesa, que comenzó a desarrollarse en el lnstitute of Perception Research a principios de los años 60, representa un punto de inflexión decisivo en el sentido de afianzar una genuina preocupación por la realización fonética de los contornos. Con la finalidad de delimitar los movimientos tonales relevantes y desestimar las variaciones sin efectos perceptivos, ’t Hart y sus colaboradores desarrollaron un método de estilización de curvas (close-copy stylization) que sustituía el trazado de F0 original por un contorno melódico artificial perceptivamente equivalente al primero. Así, la curva ‘estilizada’ representa la mínima expresión de la curva que preserva la misma información que la curva original y es el punto de partida de todo el proceso de definición de los movimientos y configuraciones relevantes (’t Hart y Collier, 1975; ’t Hart, Collier y Cohen, 1990). Asimismo, el modelo de Aix-en-Provence recoge ese interés por mantenerse fiel a la fonética del contorno y parte del análisis experimental exhaustivo de las curvas melódicas. El algoritmo MOMEL de esa escuela permite estilizar automáticamente la curva de F0 como una secuencia de puntos de inflexión (targer points): el resultado son curvas estilizadas equivalentes perceptivamente a las originales que son la base para la modelización posterior (Hirst y Di Cristo, 1998; Hirst, Di Cristo y Espesser, 2000).
El interés por el componente fonológico es también patente en esos dos modelos. La escuela holandesa, centrada en la descripción de la entonación del holandés, ha desarrollado una gramática completa de la entonación para esa lengua. Para generar cualquier contorno melódico en holandés es suficiente un repertorio de unidades fonológicas subyacentes y una gramática que especifique las combinaciones posibles de esos elementos. El módulo fonético será el responsable de la operación de mapping entre la estructura fonológica y la melodía final (’t Hart y Co llier, 1975; ’t Hart, Collier y Cohen, 1990). Asimismo, la línea programática de la escuela de Aix-en-Provence afirma que una teoría completa de la entonación debe incluir un nivel fonológico ‘profundo’ o ‘subyacente’ que dé cuenta de la competencia del locutor, es decir, que incluya las representaciones funcionales que codifican la información necesaria para la interpretación semántica y sintáctica de la prosodia de un enunciado (Hirst y Di Cristo, 1998; Hirst, Di Cristo y Espesser, 2000).
La tesis doctoral de Janet Pierrehumbert (1980), que representa el principio del enfoque métrico-autosegmental, explica en sus primeras páginas los dos objetivos centrales de su trabajo: 1) proponer un sistema de representación fonológica capaz de generar los posibles contrastes del inglés, y 2) explicitar las reglas del componente fonético que transformen la representación fonológica subyacente en el continuum de tono fundamental.
El objetivo principal de esta tesis es desarrollar una representación abstracta de la entonación del inglés que permita caracterizar los diferentes patrones entonativos que pueda adoptar un texto y explicar cómo se implementan en diferentes estructuras métricas. El segundo objetivo es establecer las reglas que transforman esas representaciones fonológicas en representaciones fonéticas. Esos dos objetivos se pueden considerar complementarios, ya que la investigación sobre las unidades subyacentes más simples debe realizarse mediante la exploración de aquellas propiedades de la representación fonética final que se derivan por regla durante la derivación y que no hay que marcar en la representación subyacente (Pierrehumbert, 1980:10). [mi traducción][1].
En el modelo métrico existen dos clases básicas de reglas encaminadas a definir la implementación fonética de los contornos: 1) las reglas de asociación entre las unidades tonales subyacentes y el texto: 2) las reglas de interpolación fonética, que se ocupan de generar los movimientos melódicos intermedios que conectan los elementos fonológicos subyacentes entre sí. Una de las aportaciones más innovadoras del modelo métrico-autosegmental es el reconocimiento del estrecho vínculo que existe entre acentuación y entonación y del papel de la estructura métrica como eje vertebrador entre movimientos melódicos. Como apunta Liberman (1975:47), «la asociación entre texto y melodía se realiza a través de la estructura métrica». Es decir, las posiciones métricas fuertes actúan de puntos de anclaje para los movimientos melódicos relevantes del contorno, lo cual permite ‘predecir’ la aparente multiplicidad de formas de un mismo patrón en diferentes textos.
Aunque la intención de la mayor parte de modelos actuales de la entonación sea desarrollar componentes fonético-fonológicos completos, lo cierto es que falta todavía mucho trabajo en el marco de cada uno de los modelos para completar esos componentes. Es necesario todavía que los aspectos fonéticos y fonológicos se integren en el estudio de la entonación y que no existan por una parte modelos exclusivamente centrados en el análisis lingüístico y funcional de la entonación (que podrían incurrir en el grave error de obviar hechos fonéticos relevantes) y, por otra, modelos que opten por un enfoque fonético y dejen de lado el imprescindible análisis funcional.
1.3. Elementos diferenciales de los modelos entonativos
1.3.1. MODELOS GLOBALES Y MODELOS SECUENCIALES
Robert Ladd (1983:40) propone que las teorías actuales de la entonación se pueden clasificar en modelos globales (jerárquicos, o de interacción de contornos) y modelos secuenciales (o discretos), según la concepción que tengan de la organización de la estructura entonativa. Por un lado, los modelos globales defienden la existencia de dos niveles de representación tonal independientes: un componente ‘local’ que contiene una serie de unidades fonológicas más un componente ‘global’ que contiene rasgos tonales como la declinación que afectan a la frase entera. En los modelos globales, el contorno se genera mediante la información combinada de diferentes dominios prosódicos independientes que se van sobreponiendo uno sobre otro. Dos modelos que se han aplicado a la síntesis de habla, como el de Hiroya Fujisaki (Fujisaki, 1983, 1988) y el de Nina Thorsen-Grϕnnum (Thorsen, 1980a, 1980b, 1981; Grϕnnum, 1992, 1995, 1998) constituyen ejemplos de modelos globales de la entonación –véase también Llisterri et al., cap. 8 en este volumen−. Por ejemplo, Thorsen-Grϕnnum postula tres niveles de representación tonal sobrepuestos: 1) el contorno textual (textual contour), un nivel prosódico jerárquicamente superior que se encarga de definir el grado de declinación melódica que se produce a lo largo de una serie de enunciados (oraciones complejas o incluso párrafos); 2) el contorno de enunciado (uterance contour), un dominio prosódico inmediatamente inferior que contempla la pendiente de declinación en la frase; 3) el grupo acentual (stress group), una unidad que comprende una sílaba acentuada más las átonas que la siguen hasta llegar al inicio de la tónica siguiente (y sin incluirla). Para obtener los contornos melódicos finales, las configuraciones acentuales locales se sobreponen sobre la línea descendente que proviene del componente de enunciado y el textual. Otro caso claro de modelo global es el de la escuela holandesa, que contempla la diferencia entre las líneas de declinación (interiores a grupos melódicos) y las de supradeclinación (interiores a oraciones y párrafos). Como dice Garrido (cap. 4, §4.1), «el modelo lPO puede considerarse un modelo jerárquico, ya que asume la existencia de patrones melódicos de diferentes ámbitos, unos más globales (la declinación) y otros más locales (los movimientos y las configuraciones), que se combinan para la construcción de una curva melódica».
Por otra parte, los modelos secuenciales generan los contornos entonativos exclusivamente mediante la concatenación lineal de unidades fonológicas, sin referirse a otro dominio prosódico superior. La teoría métrica-autosegmental, un modelo secuencial por excelencia, genera los contornos mediante la suma de elementos tonales subyacentes, asumiendo que su forma global se deriva de la aplicación de reglas locales. Así, la declinación que se produce a lo largo del enunciado se obtiene mediante la aplicación de una regla fonológica local de escalonamiento descendente (downstep) que va bajando el nivel de altura tonal de los acentos melódicos uno a uno.
Las dos últimas décadas han presenciado un cierto debate entre los enfoques locales y globales al estudio de la entonación (Beckman, 1995; Grϕnnum, 1995; Ladd, 1994, 1996; Silverman, 1987), aunque también se ha remarcado que son visiones no tan alejadas entre sí (véase Taylor, 1992; Ladd, 1996). La adscripción a uno u otro marco teórico a menudo se ha visto condicionada por el foco y el ámbito de aplicación del estudio: mientras los modelos globales se han utilizado más a menudo en aplicaciones de síntesis de habla y se han interesado por aspectos de modelización fonética, los modelos secuenciales se han centrado en el análisis lingüístico y fonológico de la entonación. Esta relativa ‘especialización’ de los modelos explica el hecho de que actualmente contemos con modelos secuenciales con un componente fonológico explícito, pero con un componente fonético poco desarrollado (cf. el modelo métrico-autosegmental), y al revés, con modelos globales que incluyen precisos algoritmos de generación fonética de contornos pero no suficientemente versátiles como para dar cuenta de la diversidad de contornos melódicos de una lengua (cf. el modelo de Fujisaki). Creemos que el estado actual de los modelos locales y globales, pues, continúa adoleciendo en parte de una falta de integración histórica entre los aspectos fonéticos y fonológicos de la entonación.
1.3.2. NIVELES Y CONFIGURACIONES
Mientras que Henry Sweet, a finales del siglo XIX, ya propone que la unidad de descripción mínima de los contornos entonativos eran los movimentos tonales («La entonación es estacionaria, ascendente o descendente»), trabajos como el de Pike (1945), Trager y Smith (1951) y Wells (1945) argumentan que la entonación del inglés se puede analizar usando 4 niveles distintivos estáticos (Low, Mid, High y Overhigh). La vieja controversia entre el análisis por niveles y por configuraciones duró varias décadas y tuvo acérrimos detractores y defensores. Dwight Bolinger (1951), uno de los más acérrimos defensores del análisis por configuraciones, criticó el peligro de ‘sobregeneración’ del análisis por niveles. Bolinger argumenta que el análisis en 4 niveles del inglés predice la existencia de seis movimientos tonales descendentes: /41/, /42/, /43/, /32/, /31/ y /21/ y que aunque esos grados de desnivel tonal puedan existir en el continuum fonético, no tienen valor distintivo alguno en el sistema fonológico del inglés.
Hasta cierto punto se puede considerar que el viejo debate entre niveles y configuraciones continúa vigente en la actualidad, puesto que diferentes modelos actuales han optado por uno u otro sistema de representación. La escuela holandesa, por ejemplo, considera que las unidades básicas de análisis tonal son los movimientos tonales, no los niveles. En este sistema la gramática tonal del holandés consta de diez clases diferentes de movimientos (cinco de tipo ascendente y cinco de tipo descendente) que constituyen las unidades básicas de análisis melódico. En cambio, para el modelo de Aix-en-Provence, las unidades básicas de un contorno son los niveles siguientes: T (Top), o altura tonal máxima del locutor (↑); B (Bottom), o altura tonal mínima del locutor (↓); y M (Mid), valor medio del locutor (→). Igualmente, el modelo métrico-autosegmental propone una versión radical del análisis por niveles y defiende que los contornos se pueden representar adecuadamente utilizando sólo dos niveles tonales, el alto (H) y el bajo (L). Esa solución permite minimizar el problema de la sobregeneración de contornos tan criticado del análisis por niveles tradicional. La utilización de únicamente dos niveles es posible técnicamente por dos razones: por un lado, la versión de Pierrehumbert (1980) incorpora una regla de escalonamiento descendente que genera la declinación de los picos a lo largo de la frase; por otro lado, la variación en el campo tonal de las excursiones melódicas se atribuye a variaciones graduales (no fonológicas) que reflejan el nivel de énfasis del enunciado (véase Pierrehumbert, 1980).
Actualmente hay quien considera que el enfoque autosegmental ha conseguido dejar atrás y ‘superar’ hasta cierto punto la vieja confrontación entre los análisis por configuraciones y por niveles (Ladd, 1996:60-64; Pierrehumbert, 2000:14). Como dice Pierrehumbert (2000:14), «los dos modelos tradicionales tienen ventajas e inconvenientes. Los modelos de dos tonos se han convertido en un estándar porque integran las ventajas de las dos visiones y evitan sus inconvenientes». El modelo métrico-autosegmental toma como punto de partida la existencia de acentos tonales que, si bien hacen referencia a los niveles originales, también indirectamente describen el tipo de ‘contorno’ que producen esas unidades. Tomemos, por ejemplo, el par de acentos tonales bitonales expresados en la figura 1.2 (H+L* y H*+L). Mientras que el acento H+L* comienza el descenso del tono a partir del inicio de la sílaba tónica, el acento H*+L lo hace a partir del final de ésta –la línea gruesa del gráfico identifica el movimiento melódico asociado con la sílaba tónica− (para más detalles, véanse los capítulos de Hualde y Sosa, en este volumen).
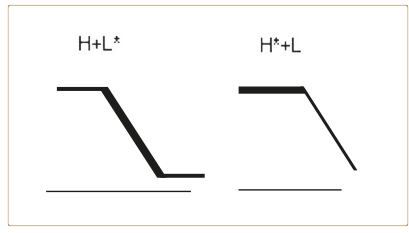
FIG. 1.2. Alineación del contorno tonal de los acentos tonales H+L* y H*+L respecto de la sílaba acentuada (Pierrehumbert, 1980).
La representación autosegmental anterior, propuesta originalmente por Pierrehumbert (1980), da cuenta del hecho de que la alineación relativa de los movimientos tonales respecto del texto tiene valor fonológico en inglés, tal como ocurre en muchas otras lenguas. En catalán, por ejemplo, el contorno melódico de la interrogativa parcial (cf. Qui l’ha llogada? ‘¿Quién la ha alquilado?’) se distingue del contorno de la interrogativa absoluta (cf. Que l’ha llogada? ‘¿La ha alquilado?’) por la sincronización del descenso tonal final respecto de la última sílaba acentuada: es decir, el inicio del descenso final de frase se sitúa o bien al final de la sílaba acentuada (H*+L) o bien al comienzo de ésta (H+L*).
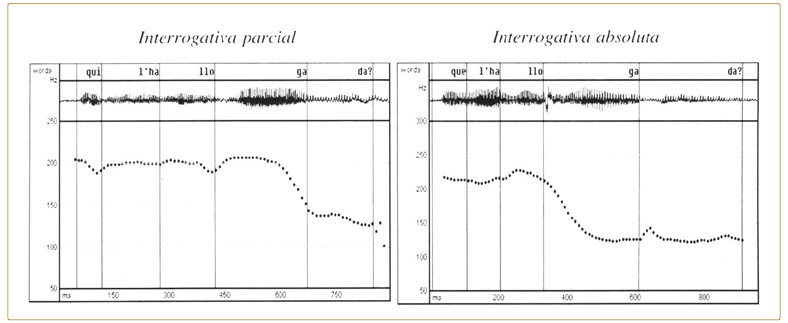
F1G. 1.3 Oscilogramas y contornos de F0 de las oraciones Qui l’ha llogada? ‘¿Quién la ha alquilado?’ y Que l’ha llogada?‘¿La ha alquilado?’ en catalán central.
En esencia, no se trata de saber exclusivamente qué ‘nivel’ recibe una determinada sílaba, sino cómo se alinean los descensos y ascensos con la sílaba acentuada, lo cual puede darnos un contraste fonológico. Precisamente uno de los inconvenientes que presenta el análisis por niveles tradicional es la falta de información relativa a la alineación de los niveles tonales con el texto. Si nos fijamos en la transcripción de la pregunta absoluta Que s’ha portat bé? ‘¿Se portó bien?’ del catalán que propone Salcioli (1988:66) en el marco estructuralista enseguida se comprueba que es ambigua respecto del lugar donde se deben emplazar los niveles tonales. El patrón propuesto 4-5 3 2-1 no contiene información referente a cómo se asocia el nivel 2 (u opcionalmente el nivel 1), si con el inicio o con el final de la última sílaba tónica, pese a que acabamos de comprobar que en catalán ese aspecto es crucial para distinguir una pregunta absoluta de una pregunta parcial.
| 4 | 3 | 2 |
| Que | s’ha portat | bé? |
Uno de los mayores avances que han supuesto los modelos actuales de la entonación ha sido el descubrimiento de la importancia lingüística de la alineación relativa de las inflexiones tonales respecto del texto. El modelo IPO, como el modelo autosegmental, incorpora este aspecto en su sistema de rasgos definitorios de los movimientos tonales que permiten describir la alineación relativa de los movimientos melódicos con el texto. En función del punto final del movimiento con respecto al inicio de la parte sonora de la sílaba, los movimientos se definen por medio de dos rasgos binarios: [±avanzado] ([±early]), que indica que éste finaliza cerca del inicio de la sílaba y [±retardado] ([±late]), que indica que el final del movimiento está cerca del final de la sílaba. El modelo de Aix-en-Provence, sin embargo, no contiene referencia alguna a ese aspecto de la representación y usa un sistema por niveles más parecido al tradicional.
En la última década, diferentes estudios fonéticos han demostrado que los hablantes articulan los contornos melódicos con un sorprendente grado de precisión que se manifiesta en la estabilidad que presentan las propiedades tanto de altura como de sincronización de los puntos de inflexión. En cambio, la pendiente y la velocidad de los movimientos tonales son más variables y parecen comportarse como movimientos de interpolación entre puntos de inflexión fijos. Tal como apunta Ladd, «los resultados obtenidos hasta ahora parecen corroborar la existencia de una especie de metas (targets) en el espacio tonal, hecho que confirma el estatus estático de las unidades subyacentes pronosticada por el modelo autosegmental». Es decir, el hablante intenta por todos los medios articular esos targets o puntos de inflexión y los movimientos intermedios se pueden interpretar como la consecuencia fisiológica de la transición entre niveles. Como dice el mismo autor, «cada vez se va acumulando más evidencia a favor de la sincronización controlada, lo que hace más difícil argumentar que los puntos de inflexión de F0 son simplemente determinados puntos de confluencia entre movimientos tonales. A mi parecer, ahora toca responder a quienes defienden modelos de tipo configuracional» (Ladd, 1996:68). En definitiva, para resolver cuestiones como la representación en niveles o movimientos hace falta investigar en detalle el comportamiento fonético de algunas partes de la curva melódica que permitan valorar las predicciones de visiones alternativas sobre la entonación.
1.3.3. LA ESTRUCTURA INTERNA DE LOS CONTORNOS MELÓDICOS
Según el modelo británico, las curvas melódicas se componen de los siguientes elementos o configuraciones: el núcleo (nucleus), que es el único componente obligatorio de los contornos y se define como la sílaba más prominente del enunciado, que puede ir opcionalmente precedido por la cabeza (head) y la precabeza (prehead) y seguido de una cola (tail) que tiene la función de continuar y completar el movimiento tonal iniciado por el núcleo. La precabeza comprende la porción de contorno de las primeras sílabas átonas y la cabeza la porción que va de la primera sílaba tónica hasta el inicio del núcleo. A su vez, estos elementos se suelen agrupar en contorno (o configuración) prenuclear(formado por la precabeza y la cabeza) y el contorno nuclear (formado por el núcleo más la cola), el pilar alrededor del cual se organiza la melodía del enunciado. En el siguiente esquema de la frase declarativa del inglés I came with my brother ‘Vine con mi hermano’ realizada como respuesta a Who did you come with? ‘¿Con quién viniste?’ mostramos la estructura canónica utilizada por la mayor parte de estudios de tradición británica (véase García-Lecumberri, cap. 2).
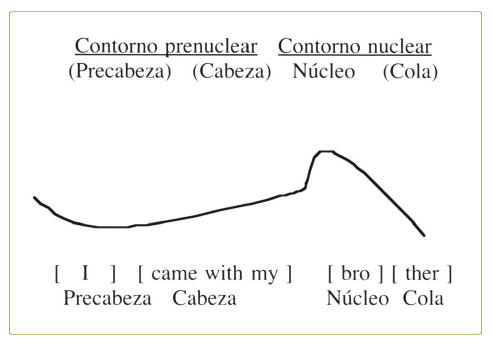
Un aspecto que diferencia el modelo americano del británico es su interpretación de los contornos entonativos como unidades sin estructura interna. Este modelo considera que el inventario de unidades fonológicas es el mismo en posición nuclear que prenuclear, aunque sí se admite la importancia entonativa que tiene la sílaba más prominente del enunciado, es decir, el núcleo. Todo patrón entonativo consta como mínimo de dos niveles tonales y una juntura terminal (véase Martínez-Celdrán, cap. 3). Igualmente, el modelo métrico-autosegmental concibe las curvas melódicas como una concatenación lineal de dos clases de unidades fonológicas: los acentos tonales (pitch accents, asociados con sílabas acentuadas) y los tonos de frontera (boundary tones, asociados con límites prosódicos), organización parcialmente heredada del modelo americano tradicional. La siguiente gramática combinatoria es capaz de generar todos los contornos bien formados del inglés (Pierrehumbert, 1980:29). Cualquier contorno entonativo puede empezar con un tono de frontera inicial opcional (%H o %L) y consta obligatoriamente de uno (o más de uno) de los siete acentos melódicos siguientes de la gramática del inglés (H*+L, L*+H, etc.). En principio, la gramática admite su libre combinación, es decir, el hablante puede ir colocando tantos acentos tonales como quiera en el orden que le plazca (Pierrehumbert, 1980:31). Finalmente, el contorno debe acabar obligatoriamente en un tono de frontera intermedia (H- o L-) seguido de un tono frontera entonativa (H% o L%). Los movimientos tonales intermedios se generan mediante reglas de interpolación del componente fonético (véase Hualde, cap. 5).
| Tonos de frontera inicial | Acentos tonales | Tonos de frontera intermedia | Tonos de frontera entonativa |
| A* | |||
| A% | B* | A− | A% |
| B% | B*+A | B− | B% |
| B+A* | |||
| A*+B | |||
| A+B* | |||
| A*+A |
FIG.1.4. Gramática combinatoria de generación de curvas melódicas del inglés. Adaptada de Pierrehumbert (1980:29).
La escuela holandesa propone que los movimientos subyacentes básicos se combinan para producir estructuras superiores llamadas configuraciones, que a su vez se concatenan siguiendo reglas de combinación específicas para formar contornos melódicos. La tipología de configuraciones está en parte inspirada en la tradición británica: 1) configuraciones ‘raíz’, o configuraciones obligatorias situadas sobre el acento más prominente de la frase −equivalente al concepto de núcleo en la tradición británica−; 2) configuraciones ‘prefijo’, o configuraciones opcionales que preceden a las configuraciones raíz y que se pueden repetir −equivalente la configuración prenuclear−; 3) configuraciones ‘sufijo’, o configuraciones opcionales que se sitúan detrás de las configuraciones raíz −equivalente a la cola (véase Garrido, cap. 4).
A mi parecer, la hipótesis defendida por el modelo autosegmental de que el hablante puede combinar como le plazca diferentes tipos de acentos tonales para formar un determinado contorno es excesivamente fuerte. El análisis pormenorizado de la entonación del catalán nos demuestra que existen restricciones combinatorias entre acentos tonales, de forma que un determinado tonema final sólo puede combinarse con un determinado elemento inicial de oración (Prieto, 2002), hecho que parece abogar por la unidad intrínseca del contorno entonativo (véase también Ladd, 1996).
1.3.4. DECLINACIÓN Y ESCALONAMIENTO DESCENDENTE
En la mayoría de lenguas se constata que la curva tonal típicamente desciende a lo largo del enunciado. Este fenómeno de declive, en el cual tanto los límites superior como inferior del campo tonal van ‘declinando’ progresivamente, se conoce con el nombre genérico de declinación (downdrift, declination). El siguiente contorno melódico de la oración declarativa del catalán La Marina vol demanar-l’hi pone de manifiesto el declive tonal de los picos. Durante mucho tiempo se creyó que todo declive tonal respondía a un mecanismo fisiológico y semiautomático de producción del habla atribuible al descenso gradual de la presión subglotal, hasta el punto que algunos lingüistas lo han considerado un universal de la producción entonativa (Lieberman, 1967; Fujisaki, 1983, 1988; Lieberman y Blumstein, 1990). Según Lieberman (1967:38), «hay una base fisiológica innata que explica la “forma” descendente del grupo de respiración que ocurre en tantas lenguas».
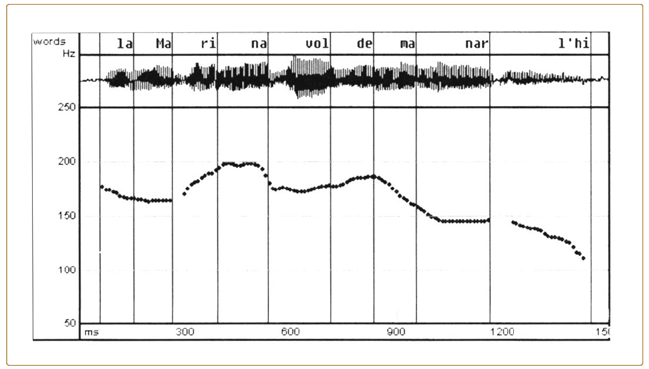
F1G.1.5. Oscilograma y contorno de F0 de la oración La Marina vol demanar-l’hi ‘Marina quiere pedírselo’ en catalán central.
Recientemente se ha puesto de relieve que hay un tipo de descenso tonal en varias lenguas que no proviene únicamente de un fenómeno universal de producción del habla, sino de un mecanismo que los hablantes utilizan con fines claramente lingüísticos. En muchas lenguas tonales africanas la secuencia tonal H..L.. H..L.. H..L..H (H=tono alto; L=tono bajo) se realiza fonéticamente como una serie de picos tonales que van descendiendo progresivamente. Es relativamente fácil de demostrar que ese descenso está condicionado fonológicamente por la presencia del tono bajo (L) entre dos tonos altos consecutivos (H), puesto que cuando las secuencias están formadas exclusivamente por tonos altos H.. H.. H.. H, el contorno presenta una pendiente de declinación significativamente menor. Tradicionalmente, las lenguas tonales distinguen dos tipos de descenso tonal: 1) un descenso producido por un proceso fonológico condicionado por la presencia de tonos bajos −también conocido con el nombre de escalonamiento descendente (downstep)−, y 2) un descenso tonal de menor magnitud producido por un efecto temporal llamado declinación −para una discusión detallada de la diferencia entre escalonamiento descendente y declinación, véase Ladd (1984).
El estudio de Liberman y Pierrehumbert (1984), uno de los primeros análisis pormenorizados de la altura de los picos tonales en inglés, descubrió un cierto paralelismo entre el comportamiento del inglés y el de las lenguas tonales. En ese estudio demostraron que la altura de los picos melódicos en oraciones declarativas se puede predecir únicamente a partir de la altura del pico anterior, sin tener en cuenta la distancia temporal entre picos. Si el descenso tonal fuera producido por un efecto temporal de declinación, esperaríamos que la magnitud del descenso fuera mayor en casos en los cuales la distancia temporal entre picos es mayor. Sin embargo, el valor en hercios de cualquier pico tonal es siempre una proporción tonal fija (o fracción constante) del valor del pico anterior (downstep ratio). En el artículo «Pitch Downtrend in Spanish », Prieto et al. (1996) comprueban que el descenso que se observa entre picos en español es, como en inglés, una fracción constante del pico precedente y no depende en absoluto de un factor de distancia temporal entre picos. El corpus de estudio fue diseñado para poder analizar el efecto que produce el incremento progresivo del número de sílabas átonas entre dos acentos melódicos altos (H) sobre la altura del segundo pico y los resultados demuestran claramente que no hay diferencias significativas entre la altura de picos situados a diferentes distancias respecto del acento tonal anterior.
En definitiva, los resultados de los experimentos anteriores son una prueba más de que el descenso tonal en lenguas entonativas no es sólo producto de un mecanismo automático de declinación sino también de un proceso intencionado que pertenece al componente fonológico de la lengua, el escalonamiento descendente. Algo que demuestra claramente que el declive tonal puede ser controlado por el locutor es el contraste que se observa entre enunciados interrogativos y declarativos. Los dos contornos interrogativos del catalán [(Que) vols l’amanida amb allioli? ‘¿Quieres ensalada con alioli?’ y (Qui) vol l’amanida amb allioli? ‘¿Quién quiere ensalada con alioli?’] demuestran que la declinación es prácticamente nula en estas oraciones, ya que el contorno se mantiene en una tonalidad alta y sostenida desde el inicio hasta la última sílaba acentuada.
Actualmente hay un debate sobre la posible coexistencia de una declinación fonológica o escalonamiento descendente (responsable de un descenso sustancial del tono) y de una declinación fonética (responsable de una declinación fonética mínima, función exclusiva de la distancia temporal). Autores como Poser (1985) y Beckman y Pierrehumbert (1988) sugieren que el descenso tonal en japonés se produce mediante la acción combinada de los dos mecanismos.
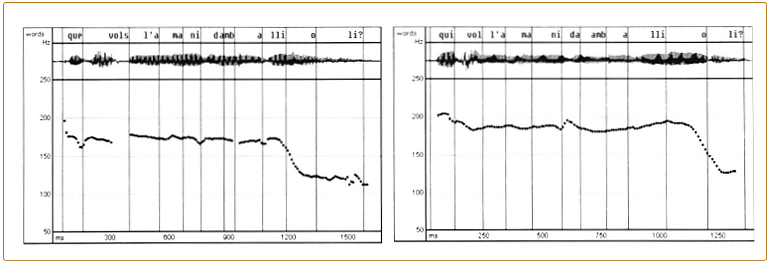 FIG. 1.6. Oscilogramas y contornos de F0 de las oraciones (Que) vol l’amanida amb allioli? ‘¿Quieres ensalada con alioli?’ y (Qui) vol l’amanida amb allioli’l? ‘¿Quién quiere ensalada con alioli?’.
FIG. 1.6. Oscilogramas y contornos de F0 de las oraciones (Que) vol l’amanida amb allioli? ‘¿Quieres ensalada con alioli?’ y (Qui) vol l’amanida amb allioli’l? ‘¿Quién quiere ensalada con alioli?’.
La investigación sobre el comportamiento de la declinación es crucial para poder valorar la certeza de las predicciones de los modelos globales y locales de la entonación. Un modelo estrictamente local como el métrico-autosegmental considera que el hablante controla de forma local el descenso de picos tonales sucesivos, y por tanto, predice que el descenso de un pico tonal no se va a modificar en función de la distancia temporal al acento anterior o en función de aspectos de tipo oracional como la modalidad. Si se demuestra que el factor temporal influye significativamente en el descenso tonal, entonces habrá indicios para suponer que el hablante tiene un control ‘global’ de la declinación y hará falta referirse a un dominio independiente referido al dominio de frase.
1.3.5. EL CAMPO TONAL
Técnicamente, el campo tonal de una inflexión (accent range, pitch range) se define como el intervalo existente entre el valle y el pico de una inflexión ascendente o entre el pico y el valle de una inflexión descendente. Por ejemplo, una de las diferencias más obvias que existe entre la entonación declarativa y la exclamativa suele ser el campo tonal que ocupan las inflexiones. En los siguientes contornos del catalán Viuran a Vilamalla ‘Vivirán en Vilamalla’ se puede observar cómo el primer movimiento ascendente tiene un campo tonal mucho más amplio en la exclamativa (unos 100 Hz) que en la declarativa (unos 40 Hz). Otra diferencia es que el último acento presenta un tono descendente en la declarativa y ascendente en la exclamativa.
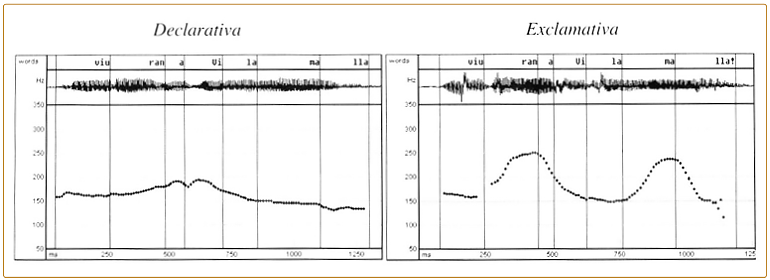 FIG. 1.7. Oscilogramas y contornos de F0 de las oraciones declarativa y exclamativa de la secuencia Viuran a Vilamalla ‘Vivirán en Vilamalla’ en catalán central.
FIG. 1.7. Oscilogramas y contornos de F0 de las oraciones declarativa y exclamativa de la secuencia Viuran a Vilamalla ‘Vivirán en Vilamalla’ en catalán central.
Una de las propuestas más radicales del modelo autosegmental consiste en considerar que el campo tonal de los acentos melódicos se amplía o se reduce en el componente fonético en función de la implicación del hablante en la emisión del enunciado, de tal manera que cuanto más enfático sea un enunciado más aumenta el campo tonal de la inflexión. Pierrehumbert argumenta que el campo tonal tiene un uso fundamentalmente expresivo y que no precisa de representación en la forma fonológica: «El inglés hace un uso muy frecuente de las variaciones del campo tonal, de forma que un mismo contorno puede ser pronunciado con tesituras tonales muy diversas. El lector puede darse cuenta de esto si intenta llamar a alguien que se imagina que está en la misma habitación y luego de llamar a alguien al otro lado de la calle». Así, se asume que las variaciones de campo tonal son un fenómeno de tipo gradual que pertenece al componente fonético y que no afectan sustancialmente al significado lingüístico.
Precisamente uno de los aspectos más controvertidos de la teoría métrica-autosegmental es el estatus del campo tonal. Aunque el modelo todavía defiende que el incremento progresivo del campo tonal es un reflejo directo de la implicación del hablante en el acto de habla, existen una serie de fenómenos que ponen de manifiesto que en algunos casos el incremento del campo tonal de un acento tonal comporta una interpretación distinta del enunciado. Trabajos como el de Ward y Hirschberg (1985) y Hirschberg y Ward (1992) demostraron mediante pruebas de percepción donde se manipuló artificialmente el intervalo tonal del acento nuclear que un mismo contorno del inglés admite dos interpretaciones posibles (incertidumbre o incredulidad) y que la aparición de una u otra depende del intervalo del campo tonal: así, una excursión tonal menor refleja un sentido de incertidumbre y una excursión tonal mayor uno de incredulidad. Los experimentos de Ladd (1990, 1994, 1996) también ponen de relieve la función contrastiva que pueden tener las variaciones de amplitud de las excursiones tonales. Asimismo, en castellano el primer pico de la oración es más alto en oraciones interrogativas e imperativas que en oraciones declarativas (Navarro Tomás, 1944; Prieto, en prensa, entre otros). Los ejemplos de la figura 1.8 ilustran este fenómeno:
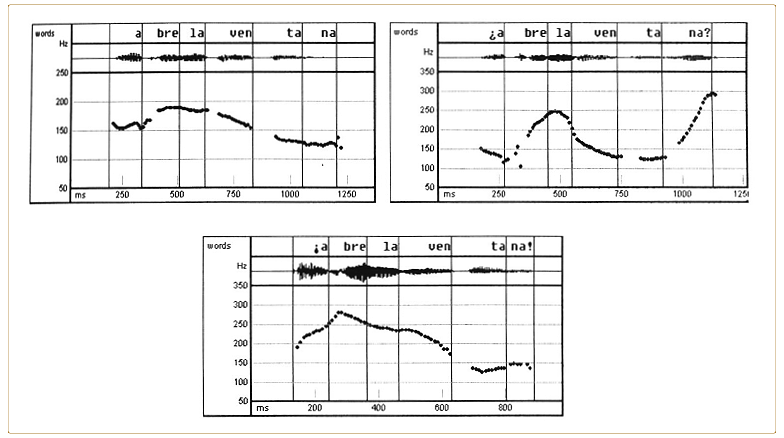 FIG. 1.8. Oscilogramas y contornos de F0 de las oraciones declarativa (gráfico superior izquierdo), interrogativa (gráfico superior derecho) y exclamativa (gráfico inferior) de la secuencia Abre la ventana en español peninsular.
FIG. 1.8. Oscilogramas y contornos de F0 de las oraciones declarativa (gráfico superior izquierdo), interrogativa (gráfico superior derecho) y exclamativa (gráfico inferior) de la secuencia Abre la ventana en español peninsular.
Beckman (1995) menciona casos parecidos del coreano, del japonés y del kipare en los cuales ampliar o reducir el campo tonal de un acento tiene efectos contrastivos. Beckman sugiere que este fenómeno se podría atribuir a un proceso de expansión del campo tonal de toda la oración (y no sólo de un acento tonal) y defiende la operatividad de un componente global que sea capaz de generar variaciones de ese parámetro. Como se podrá observar en los capítulos de Hualde y Sosa (en este volumen), una de las soluciones propuestas consiste en incorporar estos hechos de prominencia relativa directamente a la especificación tonal fonológica, por medio de rasgos/diacríticos de escalonamiento ascendente (upstep) o descendente (downstep) añadidos al tono H de acentos bitonales. Concluimos, pues, que el estatus del campo tonal es un aspecto de la teoría de la entonación que no se puede considerar resuelto en la actualidad. En las últimas líneas de su libro lntonational Phonology (1996), Robert Ladd concluye que todavía está por aclarar la función del campo tonal en la entonación de las lenguas:
Los efectos extrínsecos sobre el campo tonal no tienen por qué ser graduales y paralingüísticos. Este libro termina, pues, en el mismo punto donde empezó, es decir, intentando discernir lo que es lingüístico y paralingüístico de la entonación […] Admito que seguramente todavía no hemos establecido unos límites claros entre la lingüística y la paralingüística y que esta cuestión está todavía abierta (Ladd, 1996:283).
1.4. El futuro de los modelos de la entonación
El gran interés que despierta la prosodia en la actualidad, así como la rápida expansión de tecnologías del habla como la síntesis y el reconocimiento de voz auguran una visión optimista en un campo donde ya se ha observado un gran progreso en las últimas décadas. Uno de los grandes retos planteados en este marco de estudio es la constitución de un modelo estándar que pueda ser aceptado por la mayor parte de investigadores. Aunque el −del sistema de etiquetaje de corpus ToBI, constituye actualmente un sistema de referencia ampliamente reconocido y se ha aplicado a la descripción entonativa de un gran número de lenguas, todavía quedan por resolver aspectos controvertidos como el tratamiento de la declinación o el campo tonal (véanse los capítulos de Hualde y Sosa, en este volumen). En este sentido, una de las últimas corrientes de la fonología, la fonología de laboratorio (Laboratory Phonology; Liberman y Pierrehumbert, 1984) está contribuyendo de manera decisiva a afianzar el conocimiento de la relación entre estructura fonológica y continuum fonético y a comprobar las predicciones de modelos alternativos de la entonación. El método de la fonética experimental, pues, se ha consolidado como una técnica eficaz tanto para la evaluación de hipótesis sobre producción entonativa como para el desarrollo y control del propio modelo lingüístico de la entonación, que ha de detallar el proceso por el cual las unidades funcionales se transforman en el trazado de frecuencia fundamental.
Otro de los retos importantes planteados actualmente es el estudio de la semántica entonativa. El análisis semántico de los contornos ha sido un aspecto muy desatendido en el estudio de la entonación y la mayor parte de modelos, excepto quizás el de la escuela británica, se han concentrado en los aspectos de representación formal, dejando de lado los aspectos semánticos. Como ya remarcó Pike (1945) «cuando se analizan los significados de los contornos melódicos, el principal peligro de error −un error que ha caracterizado muchos trabajos anteriores− reside en la imposibilidad de obtener un sentido unitario a partir de un número suficientemente grande de contextos. Si se intenta extraer el sentido de un solo contexto […] se tiende a asumir que es mucho más concreto de lo que realmente es; seguro que si la muestra de contextos fuera más amplia, estas características no se atribuirían a un contorno concreto». Aunque recientemente se han hecho algunas contribuciones en este sentido, entre las que cabe resaltar la propuesta de Pierrehumbert y Hirschberg (1990) en el marco del modelo métrico-auto segmental,[2] todavía queda un largo camino por recorrer. Debemos aprovechar los conocimientos que nos brindan áreas de la lingüística como la pragmática, así como el uso de corpus prosódicos que permitan el acceso a gran cantidad de datos y faciliten una descripción fiable de los significados y matices que inscribe la entonación a los enunciados. Como dicen esas autoras, «una teoría inadecuada hará especialmente difícil establecer las interpretaciones de los contornos porque agrupará en una misma categoría contornos con significados muy desiguales o, al revés, establecerá distinciones que no tienen ningún sentido ».
Antes de iniciar la presentación de cada modelo por separado, cabe subrayar de nuevo la importancia de la combinación del trabajo experimental y el lingüístico en el futuro proceso de valoración de modelos alternativos sobre producción entonativa. Demasiado a menudo los estudios de entonación se han limitado a describir el plano acústico, dejando de lado el funcional, o al revés, se han concentrado en proponer unidades lingüísticas sin preocuparse de ponerlas en relación con el continuum melódico al que tiene acceso el oyente. Sería bueno recordar finalmente la reflexión que hacen Pierrehumbert y Hirschberg (1990) al respecto: «cualquier teoría de la entonación habrá de ser considerada provisional a menos que esté avalada a la vez por datos fonéticos y semánticos».
Referencias bibliográficas
Beckman, Mary (1995). Local shapes and global trends. En Proceedings of the lnternational Congress of Phonetic Sciences. Estocolmo, vol. 2. 100-107.
—. y Janet Pierrehumbert (1986). lntonational Structure in Japanese and English. Phonology Yearbook 3. 15-70.
Bolinger, Dwight (1951). Intonation, Levels versus Configurations. Word 7. 199-210.
Bruce, Gosta (1977). Swedish word accents in sentence perspective. Lund: CWK Gleerup.
Fujisaki, Hiroya (1983). Dynamic Characteristics of Voice Fundamental Frequency in Speech and Singing. En P. F. MacNeilage (ed.) The Production of Speech. Nueva York: Springer Verlag. 39-55.
—. (1988). A note on the physiological and physical basis for the phrase and accent components in the voice fundamental frequency contour. En Osamu Fujimura (ed.), Vocal Physiology, voice production, mechanisms and functions. Nueva York: Raven. 347-355.
Grϕnnum, Nina (1992). The Groundworks of Danish lntonation. Copenhague: Museum Tusculanum Press.
—. (1995). Superposition and subordination in intonation. A non-linear approach. En Proceedings of the lnternational Congress of Phonetic Sciences. Estocolmo, vol. 2. 108-115.
—. (1998). Intonation in Danish. En Daniel Hirst y Albert di Cristo (eds.) lntonation Systems, A Survey of Twenty Languages. Cambridge: Cambridge University Press. 131-151.
Hirschberg, Julia y Ward, Gregory (1992). The influence of pitch range, duration, amplitude and spectral features on the interpretation of the rise-fall-rise intonation contour in English. Journal of Phonetics 20. 241-251.
Hirst, Daniel y Di Cristo, Albert (eds.) (1998). lntonation Systems, A Survey of Twenty Languages. Cambridge: Cambridge University Press.
Hirst, Daniel; Di Cristo, Albert y Espesser, Robert (2000). Levels of representation and levels of analysis for the description of intonation systems. En Home, Merle (ed.) Prosody: Theory and Experiment. Dordrecht: Kluwer Academic Press. 51-87.
Ladd, D. Robert (1983). Peak features and overall slope. En Anne Cutler y D. Robert Ladd (eds.) Prosody, Models and Measurements. Berlín: Springer-Verlag. 39-52.
—. (1984). Declination, a review and some hypotheses. Phonology Yearbook l. 53-74.
—. (1990). Metric al representation of pitch register. En John Kingston y Mary Beckman (eds.) Papers in Laborator y Phonology 1, Between the Grammar and Physics of Speech. Cambridge: Cambridge University Press. 35-37.
—. (1994). Constraints on the gradient variability of pitch range, or, Pitch level 4 lives! En Patricia A. Keating (ed.) Phonological Structure and Phonetic Form. Papers in Laboratory Phonology III. Cambridge: Cambridge University Press. 43-63.
—. (1996). Intonational phonology. Cambridge: Cambridge University Press.
Liberman, Mark (1975). The Intonational System of English. Tesis doctoral, Massachusetts Institute of Technology. Publicado por Garland Publishing, Nueva York y Londres, 1979.
—. y Janet Pierrehumbert (1984). Intonational lnvariance under Changes in Pitch Range and Length. En Mark Aronoff y R. T. Oehrle (eds.) Language Sound Structure, Studies in Phonology Presented to Morris Halle. Cambridge, Massachusetts: MIT Press. 157-233.
Lieberman, Philip (1967). lntonation, Perception and Language. Cambridge, Massachusetts: MIT Press.
—. y Sheila E. Blumstein (1990). Speech physiology, speech perception, and acoustic phonetics. Cambridge, Massachusetts: Cambridge University Press.
Navarro Tomás, Tomás (1944). Manual de entonación española. Hispanic Institute in the United States, Nueva York.
Pierrehumbert, Janet (1980). The phonetics and phonology of English intonation. Tesis doctoral, Massachusetts Institute of Technology.
—. y Mary Beckman (1988). Japanese Tone Structure. Cambridge, Massachusetts: MIT Press.
—. (2000). Tonal elements and their alignment. En Home, Merle (ed.) Prosody: Theory and Experiment. Dordrecht: Kluwer Academic Press. 11-36.
Pierrehumbert, Janet y Hirschberg, Julia (1990). The meaning of intonational contours in the interpretation of discourse. En Philip Cohen, Jerry Morgan y Marthe Pollock (eds.) lntentions in communication. Cambridge, Massachusetts: MIT Press. 271-312.
Pike, Kenneth L. (1945). The lntonation of American English. University of Michigan Press, Ann Arbor.
Poser, William J. (1985). The phonetics and phonology of tone and intonation in Japanese. Tesis doctoral. Massachusetts Institute of Technology.
Prieto, Pilar; Shih, Chilin y Nibert, Holly (1996). Pitch Downtrend in Spanish. Journal of Phonetics 24. 445-473.
Prieto, Pilar (2003). Scaling of H1 peaks in Spanish: evidence from five sentence-types. Proceedings of the XVth lnternational Congress of Phonetic Sciences. Barcelona.
Salcioli Guidi, Valeria (1988). La entonación, estudio fonético-experimental de la entonación interrogativa catalana. Tesis doctoral. Universidad de Barcelona.
Silverman, Kim E. A. (1987). The structure and processing of fundamental frequency contours. Tesis doctoral, Cambridge University, Downing College.
Stockwell, Robert P. (1972). The Role of Intonation, Reconsiderations and other Considerations. En Dwight Bolinger (ed.) lntonation, Selected Readings. Baltimore: Penguin Books. 87-109.
Taylor, Paul A. (1992). A Phonetic Model of English lntonation. Tesis doctoral, Universidad de Edimburgo.
Thorsen, Nina (1980a). A study of perception of sentence intonation, evidence from Danish. Journal of the Acoustic Society of America 67. 1014-1030.
—. (1980b). Intonation Contours and Stress Group Patterns in Declarative Sentences of Varying Length in ASC Danish. Annual Report of the lnstitute of Phonetics, University of Copenhagen 14. 1-29.
—. (1981 ). Intonation Contours and Stress Group Patterns in Declarative Sentences of Varying Length in ASC Danish. −Supplementary Data, Annual Report of the lnstitute of Phonetics. University of Copenhagen 15. 13-47.
Trager, George L. y Smith, Henry Lee (1951). Outline of English Structure. Battenburg Press, Norman, Oklahoma.
’t Hart, Johan y Collier, René (1975). Integrating different levels of intonation analysis. Journal of Phonetics 3. 235-55
—. Collier, René y Cohen, Antonie (1990). A perceptual study of intonation. An experimental-phonetic approach to speech melody. Cambridge: Cambridge University Press.
Ward, Gregory y Hirschberg, Julia (1985). lmplicating uncertainty, The pragmatics of fall-rise intonation. Language 61. 747-776.
Wells, R. S. (1945). The pitch phonemes of English. Language 21. 27-39.
[1] A lo largo de todo el capítulo, las traducciones de los textos en inglés son de la autora.
[2] Pierrehumbert y Hirschberg (1990) proponen que las unidades fonológicas subyacentes tienen un determinado sentido abstracto y defienden que el significado de los contornos se obtiene composicionalmente con la suma de los sentidos de los acentos tonales más los tonos de frontera.
Cabedo, A. (2007). Marcas prosódicas del registro coloquial en la conversación. Cauce. Revista internacional de Filología y su Didáctica, (30), 41-56.
Cantero, F. (2002). Teoría y análisis de la entonación. Barcelona: Ediciones de la Universidad de Barcelona.
Estebas Vilaplana, E. y P. Prieto (coords.) (2003): Teorías de la entonación. Barcelona, Ariel.
Fernández Planas, A. Ma. (ed.) (2016). Reflexiones sobre aspectos de la fonética y otros temas de lingüística. Barcelona: Síntesis, pp. 191-199.
Iribarren, M. (2015). Fonética y Fonología españolas. Cap. 7. Madrid: Síntesis, pp. 103-124.
Martín Butragueño, P. (2019). Fonología variable del español de México: volumen II: prosodia enunciativa. México: El Colegio de México.
Muñoz A. (2013). Escudriñando las ondas sonoras del habla. En A. Pérez, Técnicas para la investigación lingüística y otras disciplinas afines. Cap. I, México: Universidad de Colima, pp. 15-42.
Teira, T y J. Igoa. (2007). Relaciones entre la prosodia y la sintaxis en el procesamiento de oraciones. Anuario de Psicología, 38 (1), 45-69.
La onda sonora
El programa PRAAT, como hemos visto anteriormente, es un software gratuito que facilita el análisis científico del habla. Recuerde que se instala fácilmente en varios sistemas operativos (Unix, Mac y Microsoft Windows).
En este ejercicio vamos a utilizar el programa PRAAT para percibir e interpretar el tono (pitch). Al realizar estos ejercicios podrá valorar la importancia de la prosodia en los análisis fonéticos y su vinculación con las expresiones de la emoción humana. Esperamos que, mientras sigue la secuencia de cada uno de los pasos señalados en esta práctica, ejercite sus habilidades con el programa PRAAT y se divierta produciendo y escuchando diversas formas de entonación.
En el Audio 1 del programa PRAAT que aparece a continuación podemos observar, de arriba hacia abajo, el oscilograma, el espectograma y la etiquetación segmentada. Esta secuencia nos permite distinguir las cualidades y particularidades de la voz humana. Una de ellas, la frecuencia fundamental o pitch, resulta esencial para el estudio de la fonética acústica. En estos ejercicios podremos manipular el pitch para modificar la onda sonora y hacer algunas pruebas de percepción acústica
En el Audio 2 podemos observar, en el espectrograma, la secuencia de la frecuencia fundamental o pitch marcada con una línea azul. Esta línea representa, gráficamente, el grado de elevación de la tonía que asciende y desciende en el espectrograma.
Para este ejercicio utilizaremos un audio donde se oye “pues yo pienso que, que sí hay mucha fantasía”. Esta emisión fue grabada por una cantante de mediana edad en una entrevista radiofónica. El Audio 1 corresponde a esta grabación donde podemos apreciar la etiquetación junto con su oscilograma y espectrograma:
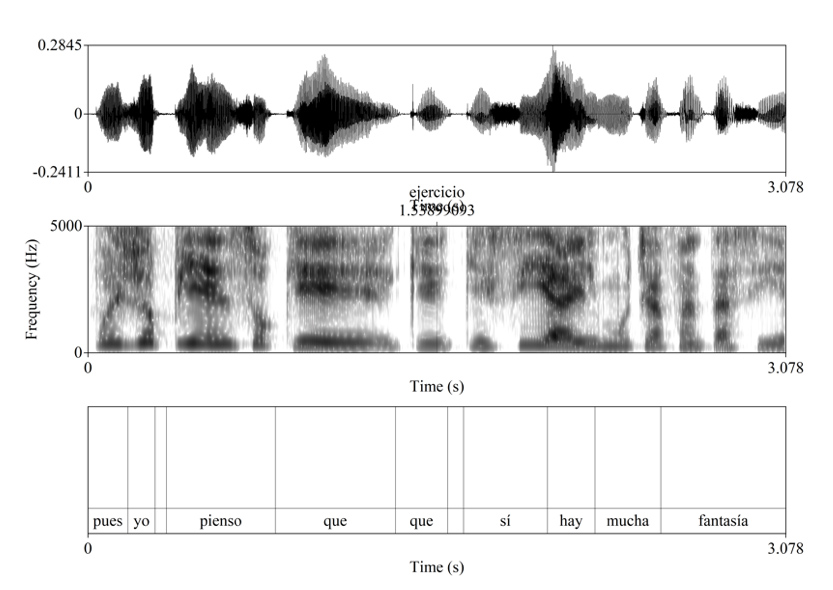
Audio1
Además de lo que se dice, podemos percibir diferentes entonaciones en la oración anterior. Esto se aprecia gracias a las curvas que muestra la frecuencia fundamental en la siguiente imagen:
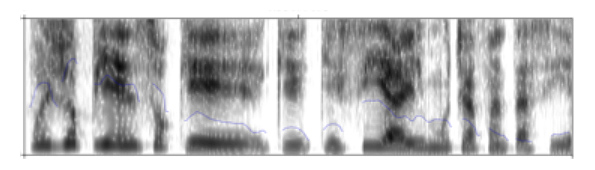
Audio 2
La línea azul en la Audio 2 muestra diferentes momentos de aumento y descenso en la frecuencia fundamental; sin embargo, hay demasiadas elevaciones como para determinar un patrón claro en la curva entonativa. Para mejorar la imagen acústica se puede hacer uso de diversos recursos en PRAAT (por ejemplo, suavizar la curva melódica extrayendo solamente el pitch del espectrograma).
Para obtener solamente la línea que muestra la frecuencia fundamental, es necesario seleccionar, en el menú “Praat Objects”, el audio que estamos trabajando, después vamos a apretar el botón “Analyse periodicity” y dar clic en “To pitch” (Ver Diapositiva 1).
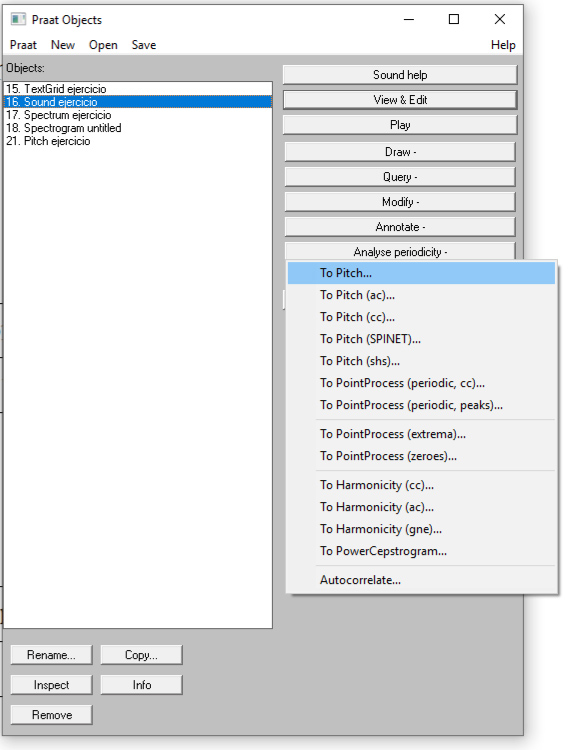
Diapositiva 1
Primero seleccionaremos, libremente, algunos de los valores que aparecen en el cuadro “Sound to Pitch” y que nos parezcan pertinentes. Una vez elegidos estos valores se mostrará un nuevo elemento llamado “Pitch (seguido del nombre de nuestro archivo)”, en el cual, al seleccionar “View & Edit”, se mostrará solamente el tono de la emisión. Esta operación eliminará cualquier ruido. Éste puede ser modificado a conveniencia, como se puede observar a continuación:
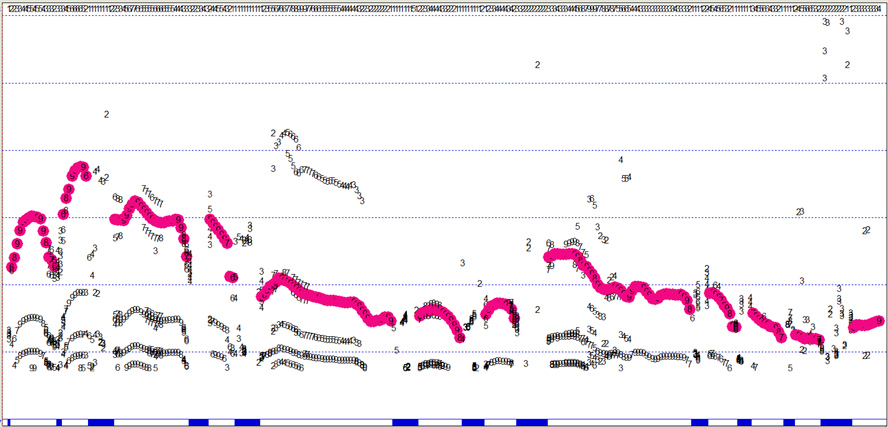 Diapositiva 2
Diapositiva 2
Además, podemos mejorar la imagen acústica del tono seleccionando el archivo “Tono…” dentro de “Praat Objects” y dando clic en “Convert” para después escoger el botón “Smooth…”:
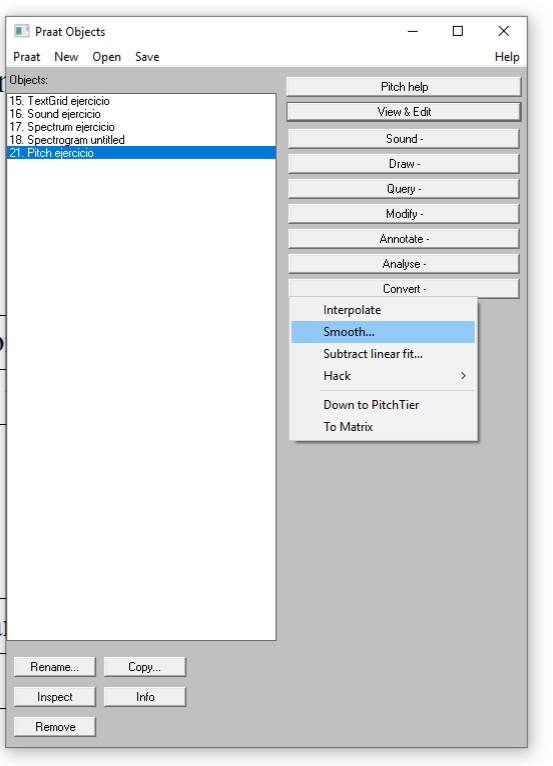
Diapositiva 3
Lo anterior dará como resultado una curva mucho más estable, lo que brinda la posibilidad de apreciar mejor la entonación de la emisión:
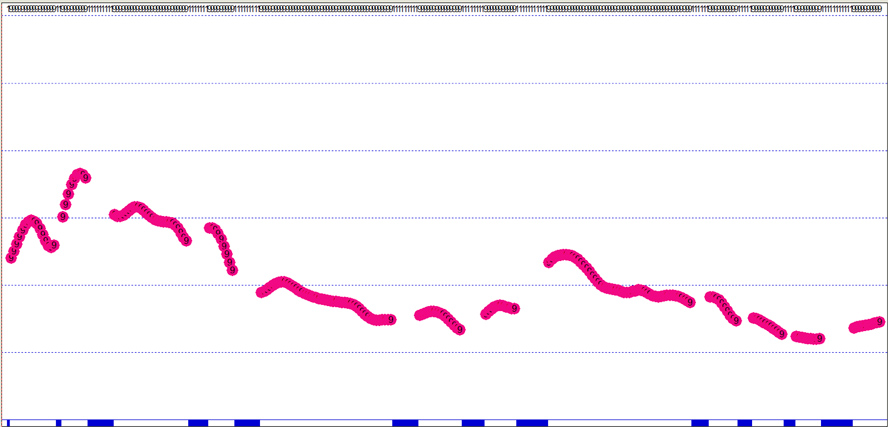
Diapositiva 4
Entre otras cosas que podemos hacer con PRAAT, se encuentra la posibilidad de alterar el pitch a conveniencia, con la intención de hacer pruebas para reflexionar sobre el tipo de entonación que nos proponemos hacer en este análisis:
Para esto, sólo necesitamos volver a seleccionar el audio que estamos trabajando y seleccionar en el menú de PRAAT la opción “Manipulate”, para después dar clic en “To Manipulation…”:
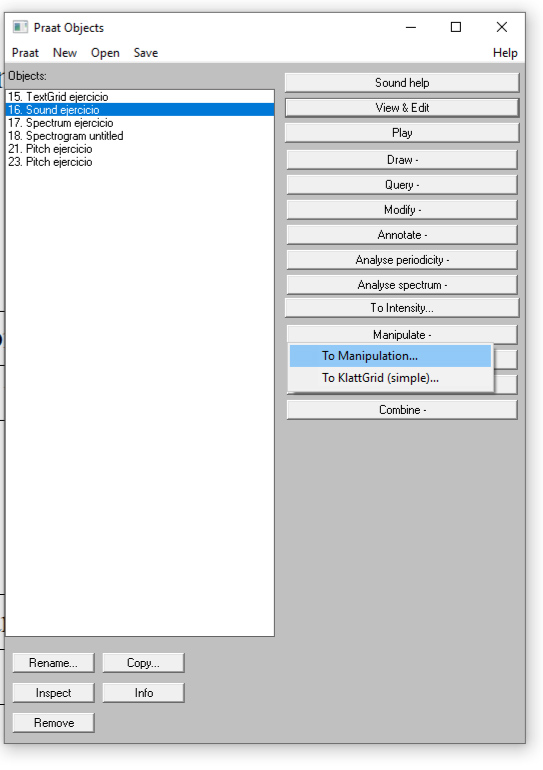
Diapositiva 5
Lo anterior generará una imagen con puntos que pueden ser borrados y movidos de tal manera que la entonación sea totalmente distinta a la de la grabación original.
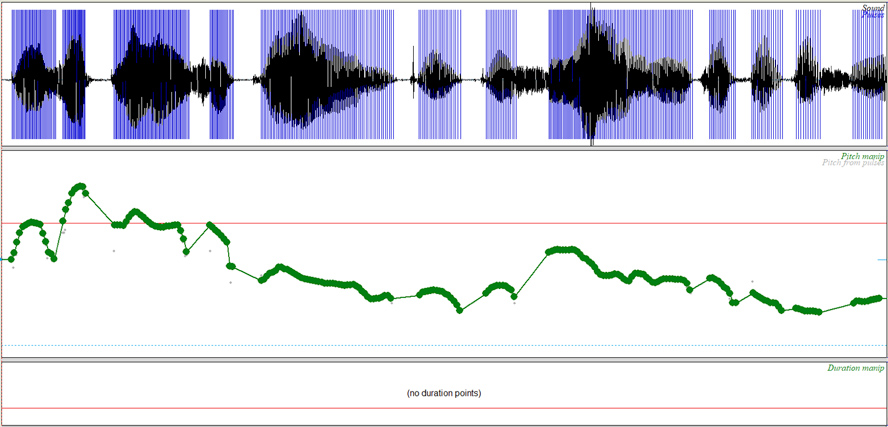
Diapositiva 6
Para remover los puntos sólo necesitamos seleccionar una sección de nuestro interés en el espectrograma y dar clic en “Remove pitch point(s)” dentro de la opción “pitch” de la barra superior.
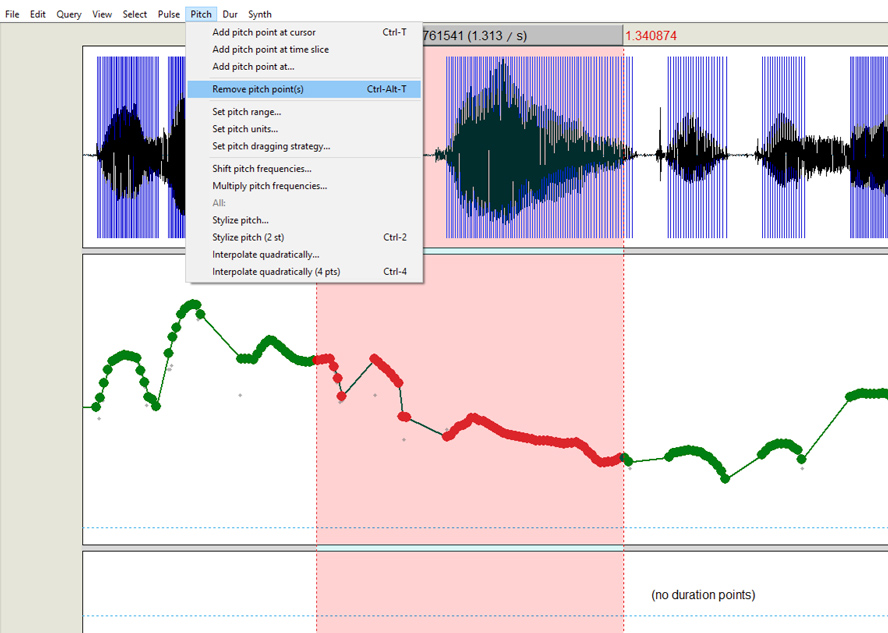
Diapositiva 7
Esto provocará que desaparezcan todos los puntos que marcan entonación dentro de la sección, como se observará a continuación en la Diapositiva 8:
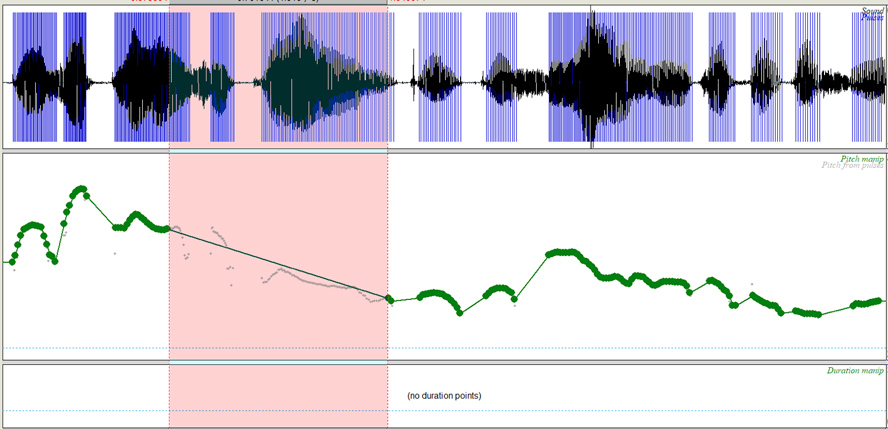
Diapositiva 8
Además, podemos modificar la posición de cada punto, lo que dará como resultado que la tonía cambie dentro de la emisión.
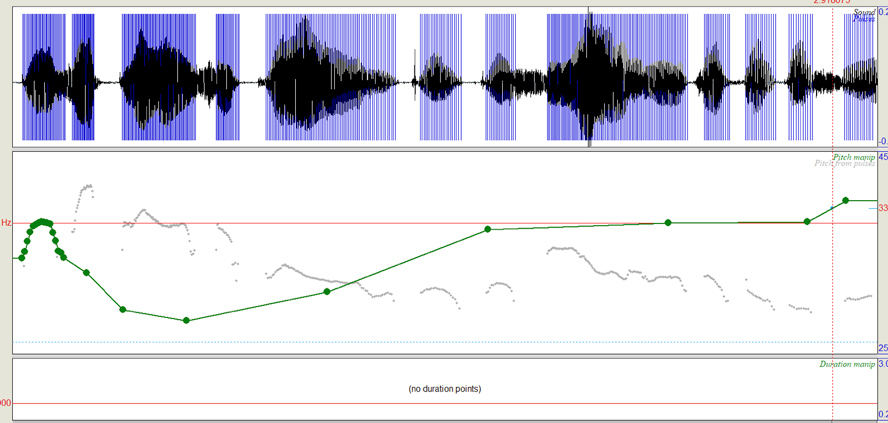
Tono ascendente
Audio 3
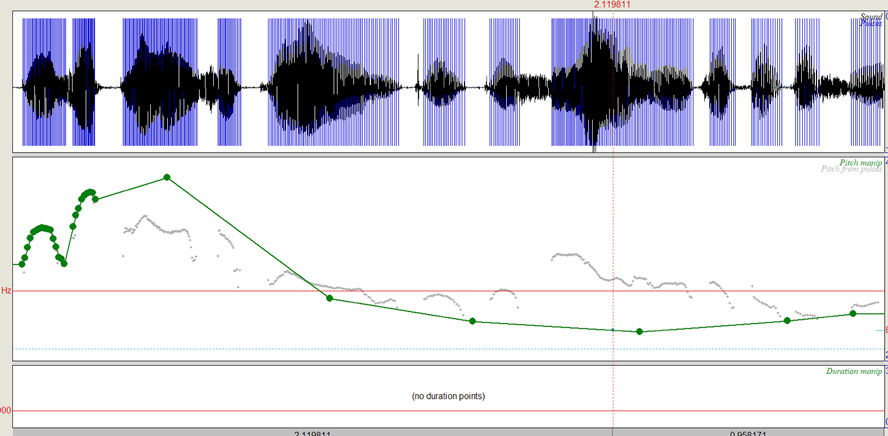
Tono descendente
Audio 4
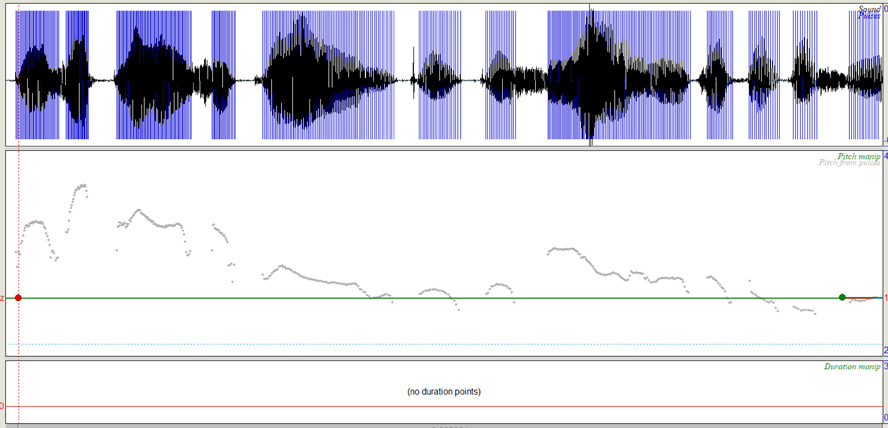
Tono sin ninguna elevación
Audio 5
Con esto, podemos generar diferentes situaciones, que pueden ser útiles para analizar y practicar las marcas entonativas de la voz.
› Siguiente sección – Ejercicio 2
Segmentos autosegmentales
Dentro de la ciudad de México existe un sin número de comerciantes con actividades específicas, los cuales requieren de diferentes métodos para que la gente reconozca, de inmediato, lo que están ofreciendo al público. Como todos ellos se encuentran en lugares concurridos o espaciosos, las palabras que dicen no suelen ser escuchadas con claridad. Por eso, han recurrido a utilizar diferentes recursos prosódicos que permiten que cualquier persona pueda identificar lo que ellos están vendiendo. Esto muestra el valor que tienen los segmentos autosegmentales, como la velocidad, número de palabras por segundo, entonación, laringización y cambio de voz modal (aspiración, nasalización) y alargamiento en algunas vocales.
A continuación se muestran algunos ejemplos de actos de habla en donde las personas utilizan diferentes recursos en sus actividades cotidianas, nuestra tarea será poder identificar en estas voces alguno de los recursos prosódicos antes mencionados.
a) “Merolico” venta de cobijas y platos en tianguis y ferias de la Ciudad de México
Video original tomado de aquí
Video original tomado de aquí
b) Venta de fierro viejo
Video original tomado de aquí
c) Venta de tamales oaxaqueños
Video original tomado de aquí
Video original tomado de aquí
d) Venta de esquites y patas de pollo
Video original tomado de aquí
e) “cacharpo” gritón de transporte público
Video original tomado de aquí
1.- Después de escuchar todas las voces ¿Cuáles son las características prosódicas que podrían identificar en cada una de ellas?
2.- Complete los siguientes cuadros para tipificar cada uno de los actos de habla que acaba de escuchar. Describa los sonidos a partir de sus características prosódicas:
a) “Merolico” venta de cobijas y platos en tianguis y ferias de la Ciudad de México
| característica prosódica | Descripción: |
| velocidad de habla | |
| tipo de voz (nasal, aspirada, laringizada, etc.) | |
| entonación (ascensos y descensos) | |
| vocales: largas, elisión, asimilación, etc. |
b) Venta de fierro viejo
| característica prosódica | Descripción: |
| velocidad de habla y número de palabras aproximadas | |
| tipo de voz (nasal, aspirada, laringizada, etc.) | |
| entonación (ascensos y descensos) | |
| vocales: largas, elisión, asimilación, etc. |
c) Venta de tamales oaxaqueños
| característica prosódica | Descripción: |
| velocidad de habla y número de palabras aproximadas | |
| tipo de voz (nasal, aspirada, laringizada, etc.) | |
| entonación (ascensos y descensos) | |
| vocales: largas, elisión, asimilación, etc. |
d) Venta de esquites y patas de pollo
| característica prosódica | Descripción: |
| velocidad de habla y número de palabras aproximadas | |
| tipo de voz (nasal, aspirada, laringizada, etc.) | |
| entonación (ascensos y descensos) | |
| vocales: largas, elisión, asimilación, etc. |
e) “cacharpo” gritón de transporte público
| característica prosódica | Descripción: |
| velocidad de habla y número de palabras aproximadas | |
| tipo de voz (nasal, aspirada, laringizada, etc.) | |
| entonación (ascensos y descensos) | |
| vocales: largas, elisión, asimilación, etc. |
3.- ¿Qué otra actividad comercial conoce que por sus características entonativas sea fácil de identificar?
4.- Una vez que haya identificado los audios por la tonía, escriba su propia reflexión sobre la importancia que tienen los cambios de entonación durante la enunciación para identificar situaciones de habla en diferentes contextos y con distintos significados.
› Siguiente sección – Ejercicio 3