› Ejercicio detonador
Lengua, cultura y … vocales.
El corrido es un género musical mexicano que pertenece a una estructura narrativa. Relata un hecho histórico, la vida de un héroe destacado del que se hace memoria o simplemente un acto cotidiano de los habitantes de una comunidad determinada. A este grupo pertenece el Corrido del mión. El corrido, además, impone, entre música y broma, un severo castigo al inocente personaje por sus malos hábitos. Ello implica una moraleja discursiva. Cante, reflexione y disfrute.
1- Vea el siguiente video para escuchar El corrido del mión, escrito por Julián Garza.
Video original tomado de aquí
- Escuche con especial atención la pronunciación de las vocales
- Trate de identificar, mientras escucha, las alteraciones que sufren algunas vocales en esta interpretación
2- Lea el texto de El corrido del mión que aparece a continuación:
Arriba de un cerro mataron a un hombre
de esos que en la noche se salen a miar
Arriba de un cerro mataron a un hombre
de esos que en la noche se salen a miar
Quien iba a pensar, quien iba a pensar
que por una miada lo iban a matar
Quien iba a pensar, quien iba a pensar
que por una miada se lo iban a echar
Era ya muy tarde, las diez de la noche
se oyeron tres tiros y un cuerpo cayó
Era ya muy tarde, las diez de la noche
se oyeron tres tiros y un cuerpo cayó
Salimos a ver que cosa pasó
tres hombres corrieron, mataron al mión
Salimos a ver que cosa pasó
tres hombres corrieron, mataron al mión
El nunca pensó que lo iban a matar
el solo pensaba en salir a miar
El nunca pensó que lo iban a matar
el solo pensaba en salir a miar
La muerte encontró, la muerte encontró,
esa gente ingrata ni miar lo dejó
La muerte encontró, la muerte encontró,
esa gente ingrata ni miar lo dejó
A los asesinos del mión que mataron
ya los agarraron paseando por ai
A los asesinos del mión que mataron
ya los agarraron paseando por ai
Ellos alegaron, pos que lo mataron
en defensa propia pos los iba a miar
Ellos alegaron, pos que lo mataron
en defensa propia pos los iba a miar
Esos tres chacales ya estan en prisión
pagando su culpa por matar al mión
Esos tres chacales ya estan en prisión
pagando su culpa por matar al mión
El juez sentenció, el juez sentenció
diez años de cárcel por esa traición
El juez sentenció, el juez sentenció
diez años de cárcel por esa traición
3- Lea y escuche, al mismo tiempo El corrido del mión para identificar y marcar los cambios que sufren algunas vocales.
- Copie y pegue el texto de la letra en el espacio de abajo.
- Marque la división de las sílabas con un punto (.) de acuerdo con la interpretación que escucha. Por ejemplo:
A.rri.ba. de un. ce.rro. ma.ta.ro. n a u.n hom.bre.
de e.sos. que en. la. no.che. se. sa.le. n a. miar.
Quien iba a pensar, quien iba a pensar
que por una miada lo iban a matar
Era ya muy tarde, las diez de la noche
se oyeron tres tiros y un cuerpo cayó
Salimos a ver que cosa pasó
tres hombres corrieron, mataron al mión
El nunca pensó que lo iban a matar
el solo pensaba en salir a miar
La muerte encontró, la muerte encontró,
esa gente ingrata ni miar lo dejó
A los asesinos del mión que mataron
ya los agarraron paseando por ai
Ellos alegaron, pos que lo mataron
en defensa propia pos los iba a miar
Esos tres chacales ya estan en prisión
pagando su culpa por matar al mión
El juez sentenció, el juez sentenció
diez años de cárcel por esa traición
4- Como podrá observar, algunas vocales se modifican en la secuencia de la interpretación del texto. Imprima en una hoja el texto y marque con rojo, estos cambios. Por ejemplo:
A.rri.ba. de un. ce.rro. ma.ta.ro. n a u.n hom.bre.
de e.sos. que en. la. no.che. se. sa.le. n a. miar.
5- Si le gustó el corrido, escuche y cante el corrido para reflexionar y contestar la siguiente pregunta: ¿Así hablamos?
Distribución complementaria y variación libre
En este apartado es preciso aludir al concepto de distribución, este concepto se rige por la regla que señala que nunca nos encontraremos un sonido en el contexto fónico reservado para otro sonido, este tipo de patrón se llama distribución complementaria, pues la posición en que encontramos ambos sonidos se complementa. Recordemos que un alófono es la variante de un fonema, es decir la pronunciación de un fonema según la posición que presenta en el contexto fónico, por ello se alude a la alofonía; sin embargo, puede suceder que se seleccione un alófono, en lugar de otro y que dicha elección no se deba al contexto fónico en que se encuentre el segmento sino a factores como son los dialectales, sociales, generacionales, etc., en este caso estaremos hablando de variación libre.
Las vocales y la sílaba: preámbulo al concepto de sílaba
Desde la perspectiva fonológica, las vocales son las únicas que producen sonidos capaces de formar núcleos silábicos, a diferencia de las consonantes; esta característica, además del paso libre del aire por la cavidad bucal será un aspecto que debamos tomar en cuenta cuando se describan las vocales. Por ello, para continuar es necesario revisar brevemente el concepto de sílaba, pues en el apartado de la unidad 6 de esta página se ahondará en su descripción y análisis.
De manera clara Juana Gil señala que el concepto de sílaba es uno de los más complejos de proponer a pesar de que esta “unidad” se reconoce intuitivamente por los hablantes de una lengua; dice “Es, en efecto, un hecho comprobado en todas las lenguas del mundo que los sonidos tienden a agruparse, dentro de la cadena hablada, en unidades mayores, dotadas de una entidad propia y más fácilmente aislables que los propios segmentos, los cuales reciben el nombre de sílaba […] además que es más fácil precisar lo que no es una sílaba que lo que realmente es. Es así que no la podemos hacer equivaler a una unidad ortográfica,[…] no se trata tampoco de un morfema,[…] tampoco se corresponde con un fonema, aunque en ocasiones existan sílabas constituidas por una sola de estas unidades.” (2007, p.263)
La estructura interna de la sílaba, Juana Gil (2007, p.267) la resume con precisión de la siguiente manera: el ataque o inicio, el núcleo, cima o centro y la coda. Apunta que el núcleo es es imprescindible para que pueda hablarse de sílaba, y puede estar integrado por uno o varios sonidos. El primer caso se denomina núcleo simple y, en el segundo, núcleo complejo o compuesto. Así tendremos palabras como sainete, donde la primera sílaba tiene una cima compleja formada por el diptongo [ai̯], la segunda y tercera sílaba podemos observar que son simples, pues sólo tienen una vocal.
El ataque es uno de los dos márgenes silábicos, puede ser simple, compuesto no existir. Por ejemplo: la palabra alba, la sílaba ba tiene un ataque simple formado por la consonante [b]; la sílaba al no posee ataque, en el caso de la palabra brisa, la sílaba bri presenta un ataque compuesto.
La coda silábica es el llamado margen posterior, puede ser simple, compuesta o no existir. Por ejemplo, si observamos la palabra instalar, la coda ins es compuesta pues está formada por más de un fonema, en tanto que la coda de la sílaba lar es simple pues tiene un solo fonema, y en el caso de la sílaba ta no existe coda.
Para hablar de las secuencias vocálicas en español, Juana Gil retoma a Machuca (2000) y la cita textualmente: “existen dos tipos de combinaciones vocálicas en español, las que forman parte de una sola sílaba (diptongo, triptongo) y las que pertenecen a sílabas diferentes(hiato). Constituyen diptongo aquellas combinaciones en las que aparecen vocales átonas de grado mínimo de abertura /i, u/ delante o detrás de una vocal más abierta /a, e, o/ o delante de una vocal de igual abertura /iu, ui/. Según el lugar que ocupen dichas vocales dentro de la combinación podemos distinguir entre diptongos crecientes —la lengua se desplaza desde una posición articulatoria cerrada a una abierta—, decrecientes —la lengua se desplaza desde una posición articulatoria abierta a una cerrada—, y homogéneos —la posición articulatoria siempre es cerrada. (…) Por su parte los triptongos están formados por un núcleo silábico [a, e] rodeado de dos elementos vocálicos.” (citado por Gil: 2007, p.448). Para ejemplificar el tipo de diptongos tenemos las siguientes palabras: muy, cuidado= diptongo homogéneo; plenilunio, mientras, luciérnaga = diptongo creciente; paupérrimo, astronauta, rey = diptongo decreciente
Las vocales: correspondencia articulatoria y acústica
Los estudiosos señalan que una de las diferencias centrales entre los sonidos vocálicos con los consonánticos se relaciona con la abertura de la cavidad bucal, “las vocales requieren un canal bucal más abierto porque a ejecutarse intervienen los músculos depresores de la mandíbula para que baje, lo cual permite que la lengua adopte posiciones más bajas y abiertas que aquellas que se dan durante la articulación de las consonantes. Cuando éstas se producen los músculos elevadores de la mandíbula son los que permiten la articulación, ya que la lengua puede elevarse y estar más cercana al resto de los órganos bucales. En tanto que las vocales tienen vibraciones de las cuerdas vocales por unidad de tiempo, por eso son más sonoras y presentan un tono más alto que las consonantes sonoras y una mayor tensión en su emisión” (Hidalgo Navarro y Quilis Merín: 2012, p.139) además de que adquieren un timbre, el cual es una característica relacionada con la distribución de los resonadores faríngeo y bucal.
Como se revisó en el apartado de fonología, las vocales se clasifican tomando en cuenta la posición de la lengua y el movimiento de los labios, de acuerdo con Juana Gil existen otros parámetros descriptivos que aluden a “propiedades secundarias que en ciertos casos ‘se añaden’ al timbre habitual de las vocales en él representadas”. Los parámetros que menciona son: la nasalidad, la retroflexión, la tensión y la duración. Al definir estos conceptos Juana Gil señala que son escasas las lenguas que poseen vocales retroflejas o rotarizadas: “vocales en cuya articulación el ápice de la lengua se curva hacia arriba como en la pronunciación de las consonantes vibrantes” (2007, p.50); en tanto que la tensión es “el mantenimiento de los músculos en estado de contracción o en un estado determinado” (Gil: 2007, p.150). En el caso del español “una vocal puede nasalizarse si está situada entre dos consonantes o ante una consonante nasal al principio de la emisión” (Gil, 2007, p. 50). Como se sabe en español la nasalización de las vocales no es un rasgo distintivo o una característica que incida en el significado, será entonces un aspecto alofónico, lo mismo sucede con la duración, las vocales en español pueden alargarse o acortarse de acuerdo con el contexto, pero no es un rasgo que implique un cambio de significado de las palabras.
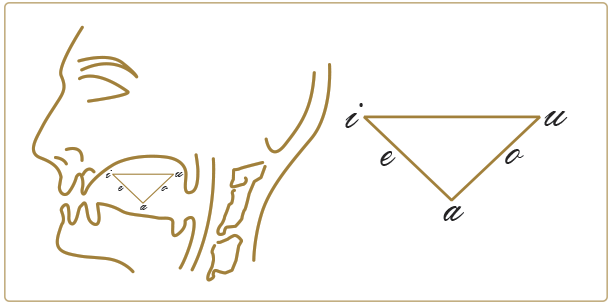
Juana Gil señala que Daniel Jones al idear el Sistema de Vocales Cardinales partió, acertadamente, de la teoría del límite vocálico, la cual toma en cuenta que “cada una de las vocales que los seres humanos podemos pronunciar, sean cuales fueren, se realiza con la parte más alta de la lengua situada dentro de un espacio bien delimitado de la boca, […] De situarse la lengua más allá de ese ámbito, obtendríamos de inmediato, con condiciones normales de volumen y velocidad de flujo de aire, una consonante aproximante o fricativa” (2007, p.429). El espacio al que se refiere Juana Gil permite ubicar las vocales en ejes, así en el límite anterior se ubica la vocal [i], que es la Vocal Cardinal número 1, pues es la vocal más cerrada y más anterior. El límite posterior está representado por la vocal [ɑ], vocal abierta posterior no redondeada, que es la más abierta y la más retraída de las vocales. Esta vocal no aparece dentro de las realizaciones de la lengua española.
Triángulo articulatorio
Modo de la articulación: Vocales altas, medias y bajas.
El modo de articulación es dependiente de la altura de la lengua y la abertura de las mandíbulas y diferencia entre vocales altas o cerradas, si la lengua se aproxima a un máximo permisible al paladar duro o blando ([i], [u]); vocales medias, cuando la lengua se encuentra en una posición intermedia en la cavidad bucal ([e], [o]) y vocales bajas o abiertas, cuando la articulación de la lengua se encuentra en la posición más baja, en el límite máximo de alejamiento ([a]). Se considera que las vocales posteriores van acompañadas de forma natural por un redondeamiento o abocinamiento de los labios denominados labialización y que las vocales anteriores son no labializadas.
Lugar de la articulación: anteriores, centrales y posteriores
El lugar de la articulación depende de la posición de la lengua. Cuando la parte predorsal de la lengua ocupa la región delantera de la cavidad bucal (el paladar duro), se originan las vocales anteriores o palatales ([i], [e]); cuando es el posdorso de la lengua el que se aproxima a la región posterior de la cavidad oral (el paladar blando), se producen las vocales posteriores o velares ([o], [u]); finalmente, si el dorso de la lengua se encuentra en la zona central de la cavidad oral se origina la vocal central [a].
Velo del paladar: orales y oronasalizadas. La acción del velo del paladar está relacionada con los sonidos vocálicos y la condición de la cavidad nasal. Si el velo del paladar se encuentra bajo, entre a zona intermedias y entre la lengua y la pared de la faringe, se produce una resonancia nasal complementaria, denominada, nasalización u oronosalización vocálica. De esta forma, las vocales nasales u oronasales se distribuyen y complementan con las vocales orales. La nasalización se da cuna una vocal se sitúa entre dos consonantes nasales [mano], o en posición inicial absoluta, después de pausa y antes de consonante nasal [anfora], [amnistía], ver Navarro Tomás (1980:39). Estas variantes son alófonos en distribución complementaria.
Las vocales son sonoras en condiciones normales y la vibración de las cuerdas vocales es un rasgo inherente de los sonidos vocálicos que sólo se pierde en el murmullo. El grado de energía articulatoria permite diferenciar entre vocales acentuadas o tónicas con mayor firmeza, abertura y perceptibilidad y vocales inacentuadas o átonas: en español no son relevantes, desde el punto de vista fonético, los casos de relajación vocálica en lo que se sigue conservando el timbre vocal (Quilis, 1993, p 185). Los rasgos mencionados anteriormente forman el triángulo articulatorio de las vocales españolas, que es un sistema de tres grados de abertura en el que se combinan el modo y el lugar de la articulación y que indica la posición de la lengua al articular sonidos vocálicos. En dos dimensiones es el llamado triángulo de Helwg:
Ya que la articulación de cada sonido está determinada por posiciones de los órganos articulatorios porque estos modifican la forma y el volumen de los resonadores bucales, estas propiedades articulatorias se relacionan con las acústicas. Desde esta perspectiva, se observa que la diferencia entre vocales es la distinta estructuración de sus armónicos o formantes descritos como “conjunto de frecuencias características del timbre de una vocal” (Quilis: 1993, p.154). Su percepción es lo que se denomina timbre.
Rasgo denso-difuso: primer formante. Para la percepción y reconocimiento de cada vocal se identifican los dos primeros formantes. El rasgo acústico denso-difuso es el grado de densidad o difusión del primer formante (F1). De acuerdo con la mayor o menor altura del primer formante, es decir, la concentración de energía en las bandas centrales del espectro de frecuencia o su dispersión hacia los extremos, se darán vocales densas y vocales difusas. Este formante tiene una relación directa con el grado de abertura de la cavidad oral, de tal manera que las vocales densas corresponden a las abiertas y las difusas a las cerradas.
Las vocales se clasifican en:
| rasgo | Vocal |
| [+denso] | /a/ |
| [-denso] | /i/
/e/ |
| [+difuso] | |
| [-difuso] | /u/ |
Rasgo agudo-grave: segundo formante. El segundo formante (F2) diferencia el timbre de las vocales, dividas en vocales graves, cuando se encuentran en una zona baja del espectro, y vocales agudas, si están en zonas más altas. De esta manera, se da una relación directa entre la posición palatal de la lengua, que presenta un F2 de frecuencia alta, y la posición velar, en la que se produce lo contrario, un F2 de frecuencia baja. Adicionalmente, el redondeamiento de los labios se relaciona al descenso de la frecuencia de F2 con respecto a otro valor. Además, hay una relación directa entre la longitud de la cavidad bucal anterior y el descenso de las frecuencias de F2; así, cuanto más larga es la cavidad anterior de resonancia, más baja es la frecuencia de F2 y viceversa.
De acuerdo con el rasgo grave-agudo, las vocales se clasifican como:
| rasgo | Vocal |
| [+grave] | /o/ /u/ |
| [-grave] | /i/
/e/ |
| [+agudo] | |
| [-agudo] | /a/ |
Nasalidad: tercer formante. El tercer formante vocálico (FN o formante nasal), se relaciona con el grado de descenso del velo de paladar en la nasalización de las vocales y se refleja en la elevación de sus frecuencias.
Las vocales españolas y las vocales cardinales. Tal como se forma, fisiológicamente, un triángulo articulatorio, también se dan los triángulos acústicos que se basan en las cartas de formantes vocálico y relacionan las llamadas vocales cardenales.
El triángulo de Helwag es muy simple para representar de manera adecuada la complejidad de los sistemas vocálicos de las distintas lenguas por lo que no es útil con fines comparativos. Por eso, D. Jones (1918) propuso un esquema teórico de “vocales cardinales” en el que se colocan todas las vocales que distingue la Asociación Fonética Internacional, en intervalos equidistantes desde las posiciones más extremas (alto y abierto, anterior y posterior). Las vocales cardinales no responden a ninguna lengua determinada, pero constituyen un sistema teórico para situar las vocales de las lenguas, de modo que se facilita su clasificación, descripción y comparación.
Quilis (1985a:175) indica que si se comparan los triángulos se observa que el /i/ del español es algo más posterior: la /e/ del español es mucho más abierto que la /e/ cardinal sin llegar a la /E/ cardinal y es también más posterior que las vocales /e/ cardinales: la /a/ del español se encuentra entre las dos /a/ y /d/ cardinales y es bastante más cerrada; la /o/ española se aproxima, sin llegar a la /a/ abierta cardinal, siendo más cerrada que esta última; la /u/ española es más posterior y algo más abierta que la /u/ cardinal.
Alófonos vocálicos
Los fonemas vocálicos tienen variantes combinatorias o alófonos que dependen de la estructura de la sílaba, de su posición en ella y de la naturaleza articulatoria de los sonidos contiguos.
Navarro Tomás (1980:46-64) describe con detalle la realización articulatoria de este conjunto de sonidos vocálicos. Él reconoce a tendencia a presentar alófonos abiertos en sílaba trabada, en contacto con las consonantes [r] vibrante múltiple y [x] velar fricativa sorda y en las agrupaciones [Ei] [xx], presentando alófonos cerrados en sílaba libre; se identifican, además, alófonos relajados. Este mismo enfoque es compartido por Alcina Blecua (1975), Canellada y Madsen (1987:19 y 24-31), o Alarcos (1981:148-150).
Otros estudios acústicos, más recientes, (Martínez Celdrán, 1984: 288-294; Quilis y Esgueva, 1983) no confirman plenamente la postura de Navarro Tomás, sobre la regularidad en la distribución complementaria, y más bien, reconocen que estas articulaciones pueden influir las preferencias individuales de cada hablante. Por eso, en un uso normal del español, sin matizaciones diatópicas, diafásicas ni diastráticas, se considerará que los fonemas vocálicos tienen en nuestra lengua dos únicos alófonos en distribución complementaria: uno nasal cuando la vocal se halla entre pausa y consonante nasal o entre dos consonantes nasales y otro ora que aparece en e resto de los casos (Quilis, 1993:168)
Diptongos y triptongos. Las vocales pueden presentarse aisladas en la sílaba o bien agruparse dos o tres de ellas en una misma sílaba. Dos vocales en la misma sílaba forman un diptongo y si son tres, un triptongo. El núcleo silábico es la vocal que presenta una mayor energía articulatoria, mayor abertura, mayor perceptibilidad, mientras que el otro sonido constituye el margen silábico que es el sonido de transición desde o hacia las consonantes contiguas.
Las secuencias vocálicas: como se señaló al inicio de esta unidad los diptongos crecientes son los conjuntos en las que se produce un desplazamiento de los órganos articulatorios de una posición cerrada hacia una más abierta. Se forman por la unión de una misma silaba de /i/, /u/ con /a/, /e/./o/. Las vocales más abiertas forman el núcleo silábico que se colocan en la segunda posición, mientras que el margen pre-nuclear está ocupado por la vocal /i/ o /u/ que recibe el nombre de semiconsonante y se transcribe fonéticamente como [j] o [w].
Ejemplos de diptongos crecientes: /ja/ patria [patria] /ie/ siete [sjete] /ue/ bueno [bweno] /io/ vio [bjo] /uo/ superfluo [su’perflwo]
Los diptongos decrecientes son conjuntos en los que se produce un desplazamiento desde el cierre hacia la abertura articulatoria: se agrupan las vocales /a/, /e/, /o/ con /i/, /u/. La vocal que forma el núcleo silábico se encuentra en primera posición y la situada en el margen silábico postnuclear, denominada semivocal, se transcribe fonéticamente como [i], [u].
Algunos ejemplos de diptongos crecientes son:
/ai/ aire [‘aire] | /au/ auto [‘auto]
Si existe confluencia de /i/ con /u/ y viceversa, esta se presentará cuando ambas vocales tengan el mismo grado de abertura, y el núcleo ocupará la vocal que reciba el acento de intensidad, lo cual puede variar en función del hablante, la situación o el dialecto (Quilis: 1993, p.179): por eso no es posible hablar de modo específico, en estos casos, de diptongo crecientes o decrecientes. Ejemplos son las distintas pronunciaciones de /bi’uda/ o /’biuda/, /fu’i/ o /´fui/.
Tres vocales en la misma sílaba forma al triptongo, con un núcleo silábico constituido por la vocal más abierta y de mayor energía articulatoria, mientras que en el margen silábico prenuclear se sitúa el elemento semiconsonántico y en el postnuclear el elemento semivocálico. Ejemplos son: buey [‘bwei], Uruguay [ur’uywai].
Hiato y sinéresis. No siempre qu se encuentran en contacto una vocal media o baja, /a/, /e/, /o/ y una alta /i/, /u/, forman una agrupación. Por el contrario, cada una de ellas puede pertenecer a una sílaba distinta y formar el núcleo de su propia sílaba: en este caso se habla de hiato. Ejemplos son: María, mío, actué, destruir, oído. Si las dos vocales son medias o una de ellas media y otra baja, también se produce el hiato: caos, aéreo, oasis, ahora, poeta. Las normas generales para la formación de diptongos e hiatos pueden variar por diferentes causas, ya sean históricas, dialectológicas o por el propio fenómeno. (Quilis, 1993: 184-186). En la lengua hablada puede producirse un fenómeno vocálico llamado sinéresis que es la fusión de las dos vocales que se encuentran en hiato en una sola sílaba formando diptongo (via-je, sua-ve) o una reducción silábica (alcohol, real, cohe-te). (Martínez Celdrán, 1984:372).
Sinalefa. El grupo de vocales formado por el enlace de palabras en el decurso fónico y pronunciado en una sola silaba se denomina sinalefa. Este encuentro de vocales puede producir agrupaciones de hasta cinco o seis elementos vocálicos: las modificaciones que pueden experimentar las vocales son las señaladas para los diptongos, triptongos y sinéresis; es decir, un grupo vocálico como [au] se pronuncia del mismo modo en automóvil, diptongo, que, en la unión, sinalefa.
La realización de una sinalefa dependerá de la abertura de las vocales, las más frecuentes son aquellas en las que se encuentra una progresión de abertura: de más abierta a más cerrada y viceversa, por ejemplo [ae] la casa espaciosa, [ea] el valle alejado. Otro caso es cuando una vocal más abierta se encuentra en el centro del grupo: [oae] se lo digo a este chico; o dos vocales de igual abertura [oe] un vino excelente.
La sinalefa no se produce cuando se da una vocal más cerrada y ésta se encuentra en el centro del grupo, porque se marca el límite silábico, ejemplo: aiue [ai-we] casa y huerta.
› Siguiente sección – Lectura obligatoria
J. Gil Fernández (1990). Las vocales: características articulatorias. En Los sonidos del lenguaje, Madrid: Síntesis, pp. 78-90.
5.3. Las vocales: características articulatorias
5.3.1. Es práctica habitual y generalizada describir las características articulatorias de las vocales y proceder a su clasificación en función de unos parámetros distintos a los considerados para llevar a cabo la de las consonantes. Éstas, como veremos, se diferencian según sea su modo de articulación (oclusivas, fricativas, etc.) y según en qué zona del tracto se produzca dicha articulación. Las vocales, en cambio, se clasifican en virtud de la posición vertical de la lengua —es decir, a partir de lo más o menos alejado del paladar que se encuentre su zona más alta—, de la posición horizontal de la lengua —esto es, de lo más o menos adelantado que se encuentre ese punto en el eje anteroposterior de la boca— y de la disposición de los labios, con o sin redondeamiento.
El primer criterio nos divide a las vocales en altas, medias y bajas o, si se prefiere, cerradas, medias y abiertas según el uso más extendido en Europa. Fijémonos en la Fig. 5.1, donde se han contrastado los perfiles que la lengua adopta en la pronunciación de las vocales castellanas [i], [e], [a], [u] y [o].
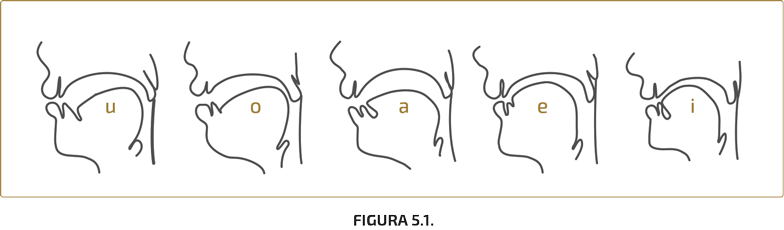
Es evidente que la parte más alta de la lengua se encuentra más próxima al cielo de la boca en las vocales [i] y [u] que en [e] y [o] y en estas últimas más que en la [a]. Por consiguiente, la [i] y [u] son cerradas, la [e] y [o] medias, y la [a]abierta.
El segundo parámetro divide a las vocales en anteriores (o palatales), si la zona más elevada de la lengua se localiza en la parte anterior de la boca, y posteriores (o velares), si, por el contrario, está situada en la zona posterior. Aún existe otro término, central, que califica a las vocales pronunciadas en la zona central de la cavidad oral. Compárense, en la Fig. 5.1, los perfiles de las vocales españolas [e], [i], claramente anteriores, con los de la [o] y [u], ambas posteriores. La [a] es central.
Vemos, pues, que mientras que en las consonantes se tiene en cuenta la situación de la zona de mayor constricción (sea ésta total, como en las oclusivas, o parcial, como en las fricativas), para establecer la localización de las vocales se considera la de la parte más alta de la lengua, que no tiene que coincidir necesariamente con el punto en que la constricción sea mayor. Como han señalado varios autores (v. Delattre: 1967, 22-23; Ladefoged: 1975, 13, entre otros), en la descripción articulatoria siempre se puede elegir entre distintas posibilidades sin que sepamos muchas veces cuál es la más acertada, porque cada una de ellas presenta, por lo general, ventajas e inconvenientes. Este sistema de especificación de las vocales es, sin duda, el más simple, pero en cambio, no refleja las considerables diferencias en la forma de la lengua para las vocales anteriores y posteriores, ni tampoco da cuenta de la variación del tamaño de la faringe en algunas de ellas, que tan apreciables cambios acústicos entraña. Por este motivo, muchos fonetistas han tratado de modificarlo, incorporando nuevos criterios, ya desde principios de siglo (v. Fischer-Jørgensen, 1985), sin que por el momento ninguna de sus innovaciones haya sido unánimemente aceptada.
Por lo que se refiere al redondeamiento de los labios, se trata de un tercer parámetro independiente de los dos anteriores y combinable con ambos. Esto quiere decir que existen vocales anteriores redondeadas y no redondeadas como se encuentran también, en muchas lenguas, vocales posteriores redondeadas y no redondeadas. Lo mismo es válido para los diversos grados de abertura: todos son combinables con una u otra disposición de los labios. Ahora bien, conviene hacer dos precisiones a este respecto.
La primera es que existe una cierta correlación entre la altura de la lengua y el grado de redondeamiento. Cuanto más cerrada es una vocal, más pequeña será la abertura que dejarán los labios al redondearse, y cuanto más abierta sea la vocal, más amplia la abertura. El abocinamiento de los labios en [u], por tanto, es mayor que el de [o], siendo, como son ambas, vocales redondeadas.
La segunda observación, ampliamente constatada, es que el redondeamiento es más frecuente en las vocales posteriores que en las anteriores. El castellano, por ejemplo, posee sólo dos elementos vocálicos redondeados, la [o] y la [u], y los dos son posteriores. Este hecho tiene, por lo demás, fácil explicación. Dado que el redondeamiento supone un descenso en el tono de la vocal, que, como detallamos más adelante, se hace más grave (véase apartado 5.4), es lógico que sean los sonidos de tonalidad ya originalmente grave —los posteriores— los que lo presentan, consiguiéndose de esta forma la máxima diferenciación perceptiva entre vocales anteriores y posteriores.
5.3.2. La descripción de las vocales en los términos anteriormente señalados, no es todo lo precisa que sería deseable. Hemos apuntado, por ejemplo, que con este sistema no se especifican las dimensiones que presenta la cavidad de resonancia faríngea en cada caso. Se ha argumentado, asimismo, que no todos los sonidos denominados altos lo son en igual media (la [u] lo es menos que la [i]), ni todos los sonidos posteriores o anteriores comparten la misma posición en el eje anterioposterior de la cavidad bucal. Sin embargo, el mayor problema generado por la falta de precisión se constata al intentar describir una vocal de una lengua concreta con referencia a las de otros idiomas, o una vocal pronunciada en un cierto momento por un hablante determinado. Si decimos, por ejemplo, que se trata de un sonido vocálico alto o cerrado, anterior o palatal y no redondeado, podemos estar refiriéndonos tanto a la [i] del español mi, como a la del inglés sit, o a la del inglés bean, etc.
Para intentar suplir esta falta de puntos de referencia, con respecto a los cuales situar cualquier eventual realización vocálica sin posible ambigüedad, el fonetista británico Daniel Jones ideó, en 1917, un sistema de Vocales Cardinales, aún empleado en la actualidad.
Adoptado por la Asociación Fonética Internacional. el sistema de Vocales Cardinales es una técnica descriptiva, cuyo dominio constituye más un arte que un conocimiento científico. Conviene tener esto presente, porque algunos de los inconvenientes que se le han encontrado provienen de una interpretación errónea del concepto.
El sistema está integrado, en efecto, por vocales teóricas (v. Monroy Casas, 1980), que no han de confundirse con fonemas. Ninguna de estas vocales debe asociarse, por tanto, con una lengua concreta, incluso aunque en tal idioma existan uno o varios elementos vocálicos coincidentes con los cardinales. Es por esto por lo que se ha repetido frecuentemente que la elección de las vocales cardinales por parte de Jones fue arbitraria, lo que no es del todo cierto si tenemos en cuenta que, para establecerlas, partió de la «teoría del límite vocálico». De acuerdo con ella, cada una de las vocales que los seres humanos podemos pronunciar, sean cuales fueren, se realiza con la parte más alta de la lengua situada dentro de un espacio bien delimitado de la boca. De situarse la lengua más allá de este ámbito, obtendríamos de inmediato, con condiciones normales de volumen y velocidad del flujo de aire, una consonante fricativa.
El límite anterior de este «espacio vocálico» está representado por la [i], que es la vocal cardinal número uno. La transcribimos con un guión suscrito porque éste es el diacrítico que diferencia estas unidades de las restantes vocales. La [i], como decimos, es la vocal más cerrada y más anterior. Si eleváramos y adelantáramos la lengua en mayor medida, pronunciaríamos una consonante fricativa palatal. El límite posterior, sin embargo, está representado por la vocal [ɑ], la más abierta y la más retrotraída de todas las vocales. De hecho, si acercáramos más a la faringe la raíz de la lengua de lo que la aproximamos al pronunciar esta vocal, la cardinal número cinco, daríamos lugar a una consonante faríngea.
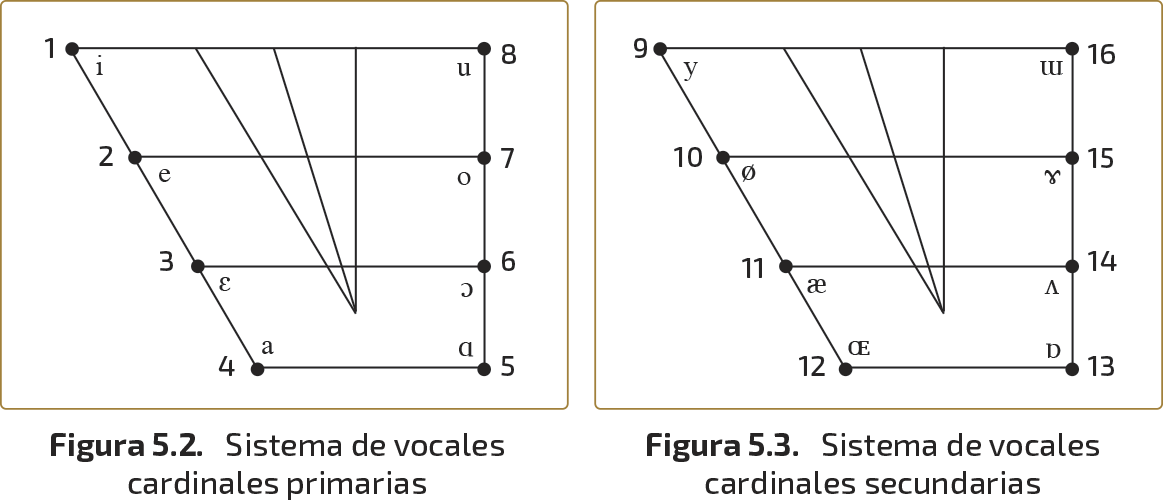
Entre ambos límites están situados otros seis sonidos auditivamente equidistantes: la vocal cardinal número dos [e], la número tres [ɛ], y la número cuatro [a], formadas todas ellas al descender poco a poco el dorso de la lengua a partir de la posición de [i]; la número seis [ɔ], la número siete [o] y la número ocho [u], resultado de la elevación gradual del dorso lingual desde la posición ocupada en [ɑ]. Así pues, existen dos series de vocales, [i–e–ɛ–a–ɑ] y [ɑ–ɔ–o–u]que mantienen entre sí distancias auditivas similares. En la Fig. 5.2, reproducimos el esquema propuesto por Jones para representarlas y que sigue siendo utilizado en la actualidad.
Las ocho vocales arriba transcritas se conocen como vocales cardinales primarias, para distinguirlas de las que ahora explicaremos, las cardinales secundarias. Evidentemente, ninguna vocal puede ser «más primaria» que otra, todas ellas son iguales. La razón de estas denominaciones no tiene, pues, nada que ver con la primacía de unas vocales sobre otras: las vocales primarias se establecieron antes que las secundarias y a ello deben su nombre.
Supongamos que pronunciamos los ocho sonidos de la Fig. 5.2 manteniendo la configuración articulatoria de cada uno de los, pero cambiando la disposición de los labios. De este modo, las vocales que antes eran redondeadas son ahora no redondeadas y viceversa, con lo que obtenemos otros ocho sonidos diferentes a los anteriores denominados vocales cardinales secundarias. Sus símbolos son [y–ø–œ–Œ–ɒ–ʌ–ɤ–ɯ] y en la Fig. 5.3 se muestra su disposición paralela a la de las primarias:
Llegar a pronunciar correctamente las vocales cardinales es una tarea ardua que requiere mucha paciencia y muchas horas de práctica. El fonetista D. Abercrombie, alumno del propio Daniel Jones, apunta a este respecto que el proceso de aprendizaje le resultó sumamente difícil, aun contando con la guía y el asesoramiento constante del creador del sistema (Abercrombie: 1985, 18). Las dieciséis vocales representadas en las Figs. 5.2 y 5.3 pueden hacerse corresponder, más o menos, con otros tantos sonidos vocálicos de diversas lenguas, según indicamos a continuación, pero tal correspondencia nunca es exacta y debe entenderse más como aproximación que como equivalencia.
- La vocal número 1, [i], es un poco más cerrada y anterior que la vocal [i] del castellano sí, por ejemplo.
- La número 2, [e], es, asimismo, mucho más cerrada que la [e] del español me y un poco más anterior.
- La número 3, [ɛ], en cambio, se asemeja a la primera vocal del francés bête o del español guerra, es decir, es mucho más abierta que la número 2.
- La número 4, [a], es más anterior que la [a] castellana —que tiende a ser posterior más que la central— y recuerda a la primera vocal francesa patte.
- [ɑ], vocal cardinal número 5, es un sonido muy posterior, semejante al de la primera [a] de ahora o de la palabra inglesa father.
- La vocal número 6, [ɔ], se parece al sonido vocálico que se emite en la palabra inglesa lost, por ejemplo, o a algunas variaciones abiertas de la [o] castellana.
- La número 7, [o] es una vocal posterior mucho más cerrada que la [o] española. Se asemeja, por tanto, a la [o] del francés pot o del inglés go.
- La vocal número 8, [u], es también más alta que la castellana [u]. Aunque recuerda a la [u] del francés tout, es un poco más posterior que esta última.
- La número 9, [y], es, en realidad, una [i] redondeada, similar a la del participio francés vu o el sustantivo alemán Mühe.
- La vocal cardinal 10, [ø], es más cerrada y anterior que el sonido de eu en la palabra francesa feu o la alemana schön.
- La número 11, [œ], es más abierta que la anterior, similar a eu en el posesivo francés leur o a la vocal alemana de zwölf.
- La vocal número 12, [Œ], es una [a] redondeada.
- La número 13, [ɒ], se asemeja a la vocal inglesa de hot, muy posterior y redondeada.
- La vocal cardinal 14, [ʌ], se corresponde con las vocales de las palabras inglesas punch o cut, a pesar de que estas suelen ser más centrales que la cardinal.
- La número 15, [ɤ], es una [o] sin redondeamiento. Vocales semejantes de encuentran fácilmente en lenguas asiáticas, como el vietnamita.
- Finalmente, la vocal cardinal número 16, [ɯ], equivale a una [u] sin labialización.
A estas dieciséis vocales de suman otras seis que son consideradas por algunos autores —no por todos (v. O’Connor: 1973, 106 y ss.)— vocales cardinales también. Tres de ellas no son redondeadas (ɨ, ɘ, ɜ) y las otras tres sí lo son (u, ɵ, ɞ). Su situación en el trapecio vocálico sería la que muestra la Fig. 5.4.
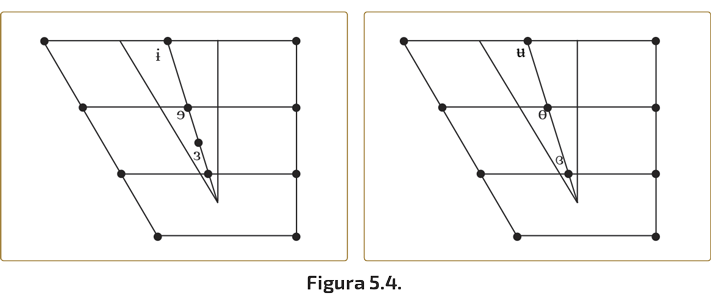
Todas ellas, como puede comprobarse en este esquema, son vocales centrales con diferentes grados de abertura.
El sistema de vocales cardinales fue concebido a partir de presupuestos de tipo auditivo (ya hemos dicho que todos estos sonidos son auditivamente equidistantes) y de tipo articulatorio (cada vocal se corresponde con una determinada posición «límite» de los órganos articulatorios). Por consiguiente, al intentar utilizarlas en la práctica fonética diaria, conviene acudir al tiempo a los dos aspectos, al auditivo y al articulatorio, apoyándonos en nuestras sensaciones de uno y otro tipo para juzgar qué relación guarda cualquier vocal con el sistema cardinal.
El procedimiento, así, constará de varios pasos. En primer lugar, de trata de reproducir en el mejor modo posible el sonido que se desea estudiar y clasificar. A continuación, se deberán examinar todos los movimientos realizados por la lengua desde esa posición hasta la cardinal más próxima y ello nos proporcionará la clave para describir el sonido investigado en relación con el cardinal. En todo momento, nuestras impresiones auditivas y de contacto articulatorio actúan como mecanismos de comprobación, de manera que las decisiones sobre la similitud o disimilitud de los sonidos son mucho más rápidas que si careciéramos de puntos de referencia.
5.3.3. Los sonidos vocálicos pueden experimentar una serie de modificaciones secundarias que afectan a sus características articulatorias y acústicas. Las más importantes son la nasalización y la retroflexión.
Las vocales nasalizadas u oronasales son aquellas durante cuya producción la úvula ha descendido, por lo que el flujo de aire proveniente de los pulmones sale al exterior a través de las cavidades nasal y oral. Para que una vocal se nasalice es preciso que existan consonantes nasales en el contexto inmediato. La primera [e] de la palabra española mente, por ejemplo, es una [e] nasalizada, que representamos [ē]. A diferencia de lo que en otras lenguas, como en francés o en portugués, en español las vocales nasalizadas no poseen valor fonológico, es decir, no sirven para distinguir significados.
Las vocales retroflejas se articulan con la punta de la lengua levantada y dirigida hacia el interior de la cavidad oral mientras toda la masa de la lengua se contrae lateralmente. Este tipo de vocales, no existentes en castellano, se escuchan con frecuencia en el inglés americano del Medio-Oeste, en palabras como shirt o car en las que la consonante [r] transmite a la vocal el «r-colouring», es decir, la retroflexión.
Estas dos modificaciones secundarias, cuyos efectos acústicos explicamos en el apartado 5.4.2, no aparecen recogidas en el sistema de vocales cardinales porque nunca alteran la naturaleza de la vocal a la que se superponen, sino que únicamente la modifican en algún aspecto.
5.3.4. A menudo se establece una diferenciación entre vocales tensas y vocales reflejadas para dar cuenta de contrastes como los que se dan entre las palabras inglesas seen («visto») y sin («pecado»), o fool («tonto») y full («lleno»). En general se considera que una vocal tensa requiere para su articulación una tensión mayor de los órganos articulatorios, asociada a una mayor deformación del tracto vocal con respeto a su posición neutra o de reposo.
A pesar de que esta distinción resulta útil desde el punto de vista fonológico, los términos en que se formulan son, cuando menos, dudosos desde el punto de vista fonético. En primer lugar, la llamada «posición neutra» es una cuestión muy controvertida. Muchos autores (v. Lass, 1976 y Catford, 1977, entre otros) consideran que, de existir, debe ser diferente para cada lengua —no universal— lo que complica extraordinariamente la descripción. En segundo lugar, el esfuerzo muscular mayor que se supone entrañan las vocales tensas no ha sido medido con exactitud y, en todo caso, ¿dónde situamos el límite?, ¿cuál es la mínima cantidad de esfuerzo muscular que nos permite catalogar un sonido como tenso? (v. Torreblanca, 1976).
Para explicar contrastes como los anteriormente citados, parece más conveniente, por tanto, hacer uso de otros parámetros. Las vocales de seen y fool son, desde luego, más altas o cerradas que las de sin y full. Además, las primeras de pronuncian con la raíz de la lengua más separada de la pared faríngea, es decir, con una cavidad faríngea de mayor tamaño que las segundas. Finalmente, las vocales de seen y fool tienen mayor duración —son más largas— que las de sin y full. Hablar de vocales anchas frente a estrechas (Ladefoged, 1975) o largas frente a breves, es, en consecuencia, preferible.
5.4. Las vocales: características acústicas
5.4.1. Como explicamos en su momento (véase apartado 2.5.1), el timbre de una vocal depende de su estructura formántica, es decir, de la disposición que presenten sus formantes en el espectro. Ya adelantamos también en anteriores apartados (véase apartado 2.5.2) que, para identificar una vocal y distinguirla de las demás, es suficiente, por regla general, especificar los valores frecuenciales de sus dos primeros formantes, F1 y F2, si bien es cierto que, en ciertas ocasiones, como veremos, se hace preciso consignar la situación del F3. La síntesis de habla ha confirmado, en efecto, que, partiendo tan sólo de los dos valores de los dos formantes más bajos, se puede reproducir adecuadamente la cualidad de la vocal que se desea simular.
A continuación, en la Fig. 5.5, presentamos el esquema que refleja la estructura formántica de las vocales españolas, confeccionado a partir de las mediciones obtenidas por Martínez Celdrán (1986).
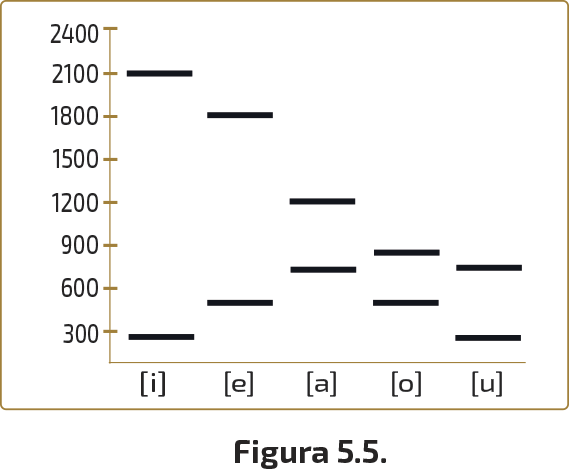
Estos valores, que, como apunta Martínez Celdrán (1986: 290), han sido calculados sobre la pronunciación de las cinco vocales aisladas por un informante masculino, varían considerablemente de un hablante a otro, en función de factores individuales (edad, sexo, características anatómicas…) o contextuales. Sin embargo, el elemento decisivo para el reconocimiento de cualquier vocal no es el valor absoluto de sus frecuencias formánticas, sino la relación que sus formantes guardan entre sí y con respecto a los formantes de las restantes vocales, por lo que las variaciones a que nos referimos no dificultan en modo alguno la comunicación.
Para medir el valor frecuencial de un determinado formante —que, recordemos, no coincide con una única frecuencia o armónico, sino que abarca a varios de ellos— pueden seguirse dos procedimientos: o bien se toma el valor de la frecuencia central del formante, sobre un espectograma de banda ancha, o bien, sobre una sección (véase apartado 3.2.5), se registra la frecuencia a la que está situado el pico más alto de la envolvente. En ambos casos, existen márgenes de error permisibles: en torno a los 20 Hz para el F1, y entre 20 y 90 Hz para el F2.
Según resulta evidente si observamos de nuevo la Fig. 5.5, existe correspondencia entre la situación del F1 y la abertura de la cavidad oral, de manera que cuanto mayor sea dicha abertura, más elevada será la frecuencia del F1. La [a] es el sonido más abierto del castellano, y, consecuentemente, su primer formante es el de frecuencia más alta. La [i] y la [u] son las vocales más cerradas y eso explica la disposición de sus F1 en la zona inferior del espectograma. La [e] y la [o] son vocales medias y sus F1 tienen también valores medios.
Asimismo, podemos comprobar en nuestra Fig. 5.5 que cuanto más anterior sea una vocal, más alto estará situado su F2y, al revés, cuanto más posterior sea la articulación, más bajo será el valor frecuencial del F2. Así, la distancia entre el F1 y el F2 en las vocales anteriores es la mayor posible.
Finalmente, cabe señalar la estrecha relación existente entre el redondeamiento o abocinamiento de los labios y el descenso de la frecuencia del F2: si redondeamos los labios estamos alargando la cavidad de resonancia oral (algunos autores piensan que, en realidad, estamos creando una nueva: véase nuestro apartado 2.1.4), y todo alargamiento de este resonador supone un descenso en el tono del sonido, es decir, un descenso de la frecuencia.
5.4.2. Como es lógico, las modificaciones articulatorias secundarias, esto es, la nasalización y la retroflexión, producen unos efectos acústicos particulares.
No existe un criterio unánime todavía sobre cuáles sean los índices acústicos responsables de que percibamos una vocal como nasalizada. Mientras que no pocos autores han supuesto que las resonancias de la cavidad nasal «se añadían» a las resonancias de la cavidad oral, apareciendo en el espectograma como nuevos formantes —los formantes nasales o FN—, las investigaciones recientes muestran que mucho más importante que la presencia de estos formantes es el debilitamiento de la intensidad de los formantes habituales, en concreto del F1. El fenómeno se comprende si tenemos en cuenta que algunas de las frecuencias que se producen en las fosas nasales se oponen a las que se originan en la boca, por lo que la energía de estas últimas se anula o se debilita en gran medida.
En cuanto a las vocales retroflejas, se observa en ellas un marcado descenso en la frecuencia del tercer formante, F3, que en nada afecta a la entidad misma de la vocal.
Otras modificaciones articulatorias posibles, tales como la velarización o la palatalización, es decir, el desplazamiento de la zona de articulación de la vocal más hacia el velo del paladar o más hacia la parte anterior de éste, se manifiestan en el espectograma por un gran descenso de F2 y F3, la primera, y por una elevación de los mismos formantes, la segunda.
5.4.3. A partir de la publicación en 1951 de la obra de Roman Jakobson, Gunnar Fant y Morris Halle, Preliminaries to Speech Analysis, las características acústicas mencionadas en los apartados anteriores, conocidas merced al desarrollo del análisis espectográfico, sirvieron de base para establecer distintas categorías de sonidos vocálicos: vocales densasfrente a difusas, graves frente a agudas, bemolizadas frente a no bemolizadas. Las oposiciones creadas de este modo poseen, en la teoría fonológica jakobsoniana, valor distintivo, esto es, tienen capacidad para diferenciar significados. Las propiedades que las definen —la densidad, la bemolización…— se denominan por ello rasgos distintivos y, al menos en la formulación clásica de la teoría, sólo pueden presentar dos especificaciones [+] o [-], sin admitir valores intermedios. Por consiguiente, si decimos que una vocal —un fonema vocálico— es [+ denso], estamos afirmando que las diversas realizaciones en el habla de ese fonema comparten un rasgo común, la densidad, por el que tal fonema se opone a otros y cuyos índices acústicos detallamos a continuación.
Los sonidos densos se caracterizan por el predominio relativo de los formantes situados en la región central del espectograma. Los difusos, en cambio, presentan un predominio de las regiones formánticas no centrales. El indicio más revelador para saber si una vocal es o no densa nos lo proporciona la posición del primer formante. En la [a] de nuestra Fig. 5.5, dicho F1 está muy alto, de modo que se trata de un sonido denso; en la [i] y la [u], difusos ambos, el F1, por el contrario, está muy bajo. La [e] y la [o] no son ni densos ni difusos: sus F1 ocupan una posición media.
Un sonido se categoriza como grave o agudo dependiendo de qué parte del espectograma predomine en cada caso: cuando lo que predomina es la parte baja, se trata de un sonido grave. Si, en cambio, predomina la parte superior del espectro, el sonido es agudo. El índice más característico de este rasgo en las vocales es la posición del segundo formante en relación con la de otros formantes. Los sonidos graves lo presentan más cerca del primer formante que los agudos, en los cuales se localiza próximo al tercer formante y demás formantes superiores. Observando de nuevo nuestra Fig. 5.5, comprobamos que la [i] y la [e] son agudas, en tanto que la [o] y la [u] son graves. La vocal [a] no es ni lo uno ni lo otro.
El de bemolización es un rasgo de tonalidad, como el anterior. Las vocales redondeadas son bemolizadas, las no redondeadas son no bemolizadas. El índice acústico que las diferencia es, según hemos dicho anteriormente, el descenso del F2 en las primeras.
Cada uno de estos rasgos, integrantes del conjunto de doce que Jakobson, Fant y Halle concibieron para diferenciar entre sí tanto vocales como consonantes, presenta considerables problemas y puede ser discutido —y de hecho lo ha sido— desde diversos puntos de vista. Pero éste no es un libro de fonología (véase la Presentación de esta obra) y, por tanto, no vamos a detenernos en examinar en profundidad tan compleja cuestión, merecedora por sí sola de toda una monografía. Conviene recordar, no obstante, que es precisamente en este punto donde fonética y fonología se acercan más actuando la primera en muchas ocasiones como disciplina de consulta a la que el fonólogo acude para confirmar sus hipótesis. En este sentido, cuanto mejor sea nuestro conocimiento de la realidad fonética, más fácil nos resultará la comprensión de los constructos fonológicos.
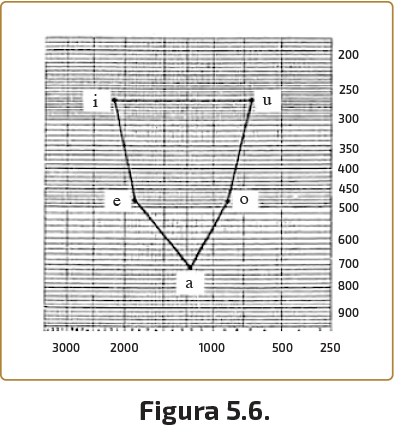
5.4.4. En la Fig. 5.6, reproducimos una carta de formantes (véase apartado 2.5.2), a la que se han trasladado los valores del F1 y F2 de las vocales españolas, de acuerdo con las mediciones proporcionadas por Martínez Celdrán. Como puede observarse, la figura que resulta si unimos los cinco puntos correspondientes a las cinco vocales es un triángulo, semejante al que el alemán C. F. Hellwag concibió en el siglo XVIII para describir los sistemas vocálicos de algunas lenguas y que normalmente se conoce como «el triángulo de Hellwag».
5.4.5. En su obra clásica Manual de Pronunciación Española, Tomás Navarro Tomás precisa cuáles son las diferentes variantes que las vocales españolas pueden presentar en función del contexto. Se distinguen variantes abiertas y cerradas para las vocales [i], [e], [o] y [u], y se señalan tres tipos diferentes de [a], la media, la palatal y la velar. Además, se diferencia entre [i] y [u] semivocales e [i] y [u] semiconsonantes.
En general, y de acuerdo con las observaciones de Navarro Tomás, las variantes cerradas aparecen en sílaba libre, salvo en el caso de la [e] cerrada, que también puede aparecer en sílaba trabada por [m], [n], [s], [d] o [θ]. Las variantes abiertas suelen producirse en sílaba trabada (para la diferencia entre sílaba trabada y libre, véase más adelante, Capítulo 7, apartado 7.1.8), en contacto con [rr], delante de [x], y, tratándose de [e] o de [o], en ciertos contextos adicionales, como los diptongos [ej] y [oj].
Las semiconsonantes y semivocales sólo pueden presentarse como componentes iniciales o finales de diptongos, respectivamente.
Por lo que respecta a las variedades de [a], Navarro indica que la palatal se encuentra ante consonantes palatales y en el diptongo [aj]; la velar, en los grupos [au] y [ao], en sílaba trabada por [l] y delante de [x]; finalmente, la media, en todos los demás contextos.
Emilio Alarcos, en su libro Fonología Española (1964), ofreció una justificación acústica para las distinciones establecidas por Navarro muchos años antes y presentó los valores frecuenciales de los formantes de cada variante. El planteamiento del ilustre fonetista se vio así corroborado, en un primer momento, por los nuevos datos brindados por los espectogramas, lo que contribuyó a que se siguiera considerando como indiscutible. Sin embargo, los resultados de las investigaciones más recientes ya no concuerdan con los de Alarcos. Si bien es cierto que existe una gran variabilidad en la realización de cada vocal, el contexto no parece ser el elemento responsable de la aparición de una u otra variante. Por el contrario, son otros factores de tipo individual, social o geográfico los que determinan el empleo de las diversas modalidades vocálicas (v. Monroy Casas, 1980). Consecuentemente, aunque admitamos la existencia de variantes, no podemos, a la vista de los resultados del análisis instrumental, prever de forma sistemática la situación en que se presentarán.
› Siguiente sección – Sugerencias
Llisterri, J. (s/a). Características articulatorias y características acústicas de los elementos segmentales. Universitat Autònoma de Barcelona Departament de Filologia Espanyola. Recuperado de:
http://liceu.uab.es/~joaquim/phonetics/fon_anal_acus/caract_acust.html#Vocales
Lope Blanch, M. (1964). En torno a las vocales caedizas del español mexicano. Nueva Revista de Filología Hispánica 17 (1-2): 1-19. Recuperado de DOI: http://dx.doi.org/10.24201/nrfh.v17i1/2.1507
› Siguiente sección – Ejercicios